Fix async #162
Fix async #162
Conversation
|
Thank you for the fix! |
| - job_name: femnist # Generate logs under this folder: log_path/job_name/time_stamp | ||
| - log_path: $FEDSCALE_HOME/benchmark # Path of log files | ||
| - num_participants: 800 # Number of participants per round, we use K=100 in our paper, large K will be much slower | ||
| - num_participants: 20 # Number of participants per round, we use K=100 in our paper, large K will be much slower |
There was a problem hiding this comment.
The comment for this param might need to be updated for async. How do we decide what to use for num_participants since there's no notion of rounds in async?
fedscale/core/resource_manager.py
Outdated
| def get_remaining(self) -> int: | ||
| """Number of tasks left in the queue | ||
| """ | ||
| return self.get_task_length() |
There was a problem hiding this comment.
Maybe the get_task_length() function could be removed in favor of get_remaining?
| return os.path.exists(self.temp_model_path_version(round)) | ||
| return os.path.exists(self.temp_model_path_version(model_id)) | ||
|
|
||
| def remove_stale_models(self, straggler_round): |
There was a problem hiding this comment.
It seems a bit inefficient to check whether the path for all the models exist during each test handler call. Seems like it would be O(N^2) time?
There was a problem hiding this comment.
Cool! We can do it in the reversed order:
while version(stale_model_id) exists: // older version should have already been removed, so we can stop
remove(stale_model_id)
stale_model_id -= 1
On the other hand, since testing is not called in every iteration, this for loop is also fine to some extent. But we will definitely optimize it. Thanks for your input!
Thanks a lot for your feedback! This PR is still WIP, since we notice the weird accuracy issue has not been well addressed (although I almost rewrote the entire async). I will fix it and your comments asap. Thanks for your patience! |
| float(self.async_buffer_size) | ||
| ).to(dtype=d_type) | ||
| d_type = self.weight_tensor_type[p] | ||
| self.model_weights[p].data = (self.model_weights[p].data/float(self.async_buffer_size)).to(dtype=d_type) |
There was a problem hiding this comment.
Dividing the model weights by async_buffer_size might not be correct since we are weighing each update by the staleness factor. Should we be dividing by the sum of the importance variable over the round?
There was a problem hiding this comment.
Or is self.model_weights[p].data the delta?
There was a problem hiding this comment.
Yes! This is really a good catch! I was wondering this too, so turned to the fedbuff paper. It turns out the paper divides the update by async_buffer_size again (Alg 1, L11). But we are happy to update it if you think it makes more sense.
There was a problem hiding this comment.
self.model_weights[p].data += delta * importance. So at this time, it becomes the latest model version.
There was a problem hiding this comment.
I have a quick question, and would greatly appreciate your input: existing FL runs the local training over a fixed number of steps, while the step here can be iteration or epoch. We find it is difficult to have a consistent implementation, though this change only takes 2-3 lines of code (e.g., by changing local_step = len(data) * local_step).
Wondering which one you prefer. We think local_step=epoch can lead to longer round duration due to the data heterogeneity. Thanks!
There was a problem hiding this comment.
I see, I think dividing by async_buffer_size is fine. However, if I understand correctly, self.model_weights[p].data = (self.model_weights[p].data/float(self.async_buffer_size)).to(dtype=d_type) is dividing the entire model weights by async_buffer_size, which might not be correct? We would want to divide just the accumulated gradients of this round by the async_buffer_size, and then multiply by a learning rate after then add that to the global model weights. Again, it could be that I'm not understanding the code correctly. 😄
There was a problem hiding this comment.
As for fixed number of steps vs len(data), I think it might make sense to have a max number of steps if possible. Then this value can be adjusted for different datasets based on use case.
There was a problem hiding this comment.
Oh! Yes! You are correct! This might even be the cause of weird accuracy. Many thanks for helping me! Let me fix it and try!
| # We need to keep the test model for specific round to avoid async mismatch | ||
| self.test_model = None | ||
|
|
||
| def tictak_client_tasks(self, sampled_clients, num_clients_to_collect): |
There was a problem hiding this comment.
In this async aggregator implementation, is there a notion of concurrency? In the PAPAYA paper, concurrency is a hyper-parameter in addition to the buffer size.
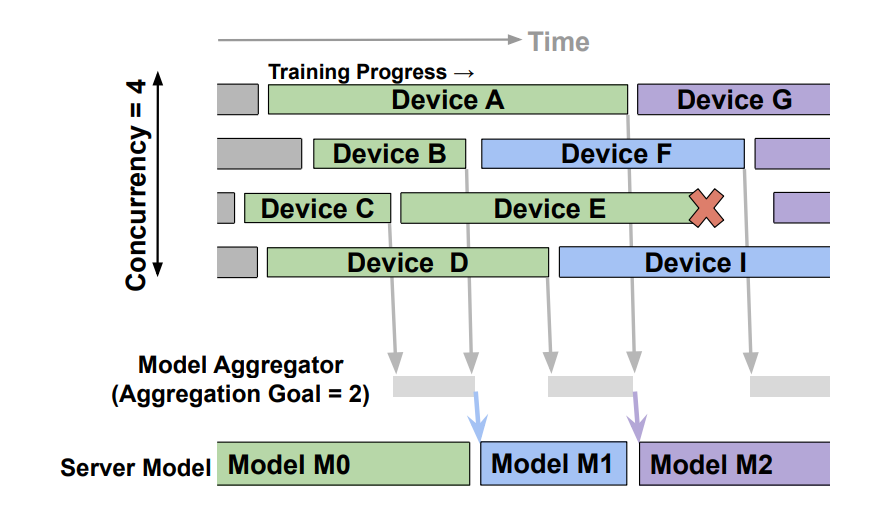
There was a problem hiding this comment.
That's a good point and sorry for not combining Papaya's design. We should do 2 more things
- add the concurrency hyper-parameter
- Make sure when assigning the training task in
tictak_client_tasks, the number of overlapping tasks doesn't exceed max_concurrency
|
Hi @AmberLJC do you have any tensorboard results for async handy? It would be helpful to attach it with the PR. Thanks! |
| # -results = {'clientId':clientId, 'update_weight': model_param, 'moving_loss': round_train_loss, | ||
| # 'trained_size': count, 'wall_duration': time_cost, 'success': is_success 'utility': utility} | ||
|
|
||
| # [Async] some clients are scheduled earlier, which should be aggregated in previous round but receive the result late |
There was a problem hiding this comment.
For my understanding: why do we want to ignore clients that should be aggregated in previous rounds? Don't we want to aggregate it anyways with a staleness factor?
There was a problem hiding this comment.
Yea, that's also a solution🤔, if we ignore the fact that the supposed end_time of the result has passed.
(The reason of receive "past" results is that we schedule the training task based on its end_time, but we cannot control the order of task finishing. )
I will either fix the grpc problem or just follow your suggestion. @fanlai0990 what do you think
There was a problem hiding this comment.
I think we can aggregate it according to the staleness factor for now.
|

|
Do you know how the convergence over virtual clock time compares with synchronous training with similar parameters? |
Let me try it out. I previously had some results, but I want to make a fair comparison again. |
| end_j += 1 | ||
| if concurreny_count > self.max_concurrency: | ||
| end_list.pop() | ||
| continue |
There was a problem hiding this comment.
By breaking the loop here, are we limiting the number of participants for each model version to max_concurrency?
For example, if we have an aggregation target of 40, and the max concurrency is set to 20, would round_completion_handler() every be called and new clients be sampled?
There was a problem hiding this comment.
I think that would not be a problem. Here I just make sure the concurrent number of participants <= 20, while it can still launch > 40 clients in a larger time window. continue does not break the loop, instead it jumps to the next loop.
(though it depends on the traces, so I need to set a larger over here)
There was a problem hiding this comment.
I see, thanks. It seems like num_participants is no longer used in the code or did I miss it?
There was a problem hiding this comment.
Yes. I have removed it.
| self.update_lock.release() | ||
| return remaining_task_num | ||
|
|
||
| def register_tasks(self, clientsToRun): |
There was a problem hiding this comment.
Do the tasks need resorting based on end time when new tasks are registered, or is there some assumption that makes this unnecessary? For example, let's say aggregation_buffer_size=1, in round 1 we have sample client_A[start=1, end= 3] and client_B [start=2,end=10]; in round 2 we sample client_C[start=5,end=8]. In round 2, we would actually get the result of client_B and aggregate it before client_C because it is earlier in the queue, even though client_C should have finished earlier.
Also, with multiple executors, the tasks might return in a different order from the original queue here. How is this handled?
There was a problem hiding this comment.
These are pretty good points.
- We can mitigate the first concern by "prefetching" more client selection in future rounds (here in async_aggregator select_participants(aggregation_buffer_size*10)).
- The second problem leads to a tradeoff between simulation efficiency and fidelity. One workaround is to stall get_next_task before clients of the current buffer_size complete;
I think we should support the 2nd point. Please let us know your feedback. Thanks!
There was a problem hiding this comment.
- That makes sense, thanks for clarifying. I think it's a valid workaround. My only concern is that with "prefetching", the difference is that round number will affect aggregation because of the staleness factor. Btw, is there a mechanism to keep the size of this queue from exploding since we are preselecting a lot?
- I think that's a good solution / option to have for correctness. Simulation speed is not a huge concern compared to the fidelity of the results. If one worker is somehow running slower than the others, then at least one result would be out of order each round, which could potentially change the results.
Thanks a lot for addressing my feedback so quickly!
There was a problem hiding this comment.
My pleasure!
- I am not pretty sure whether I have understood your concern correctly, please feel free to correct me if not.
- I think "prefetching" is fine, since we are tracking their correct "(completion) round number", thus staleness, after sorting by the completion time. Please note that the selection_round is different from the completion_round we used in aggregation. In fact, I guess we even do not care about the "selection_round", if we ignore its impact on participant_selection decisions? Admittedly, we are sacrificing the selection fidelity, but it is hard to circumvent this further in simulations.
- IMO, exploding won't be a big concern. If we assume async_buffer size is 1K, then storing 1K*10/20 indices (int64) is not a big concern? Meanwhile, since the aggregator is draining events on the fly, the event_queue won't pile up. But you are right if we are storing thousands of client updates, and that's why we are developing Redis support now (Redis Support for FedScale #170 ).
- Sounds good. I will fix this soon.
Thanks a lot for your input! :)
|
@AmberLJC Can you please help to review and test the last commit? Training gets stuck as the model (version) is missing on executors. Thanks! |
Why are these changes needed?
Related issue number
Checks