Fix async #162
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -28,7 +28,9 @@ def __init__(self, args): | |
| self.round_stamp = [0] | ||
| self.client_model_version = {} | ||
| self.virtual_client_clock = {} | ||
| self.weight_tensor_type = {} | ||
| # We need to keep the test model for specific round to avoid async mismatch | ||
| self.test_model = None | ||
|
|
||
| def tictak_client_tasks(self, sampled_clients, num_clients_to_collect): | ||
|
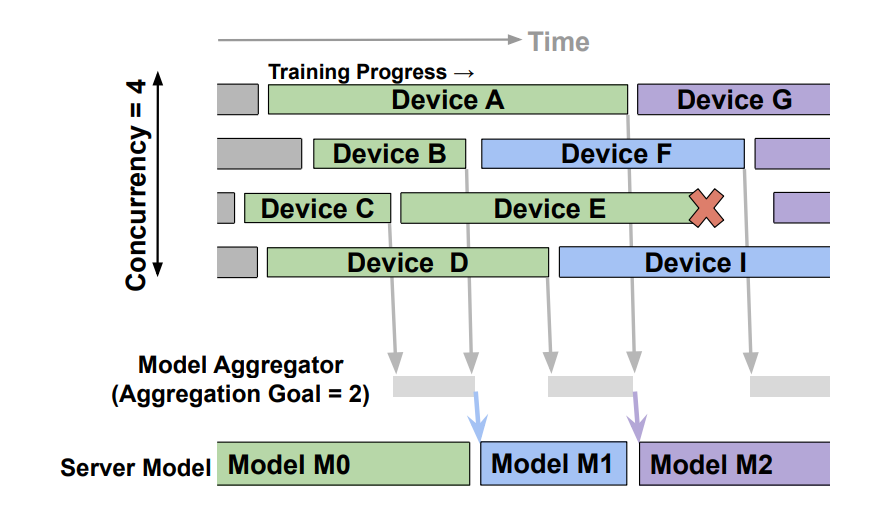
There was a problem hiding this comment. In this async aggregator implementation, is there a notion of concurrency? In the PAPAYA paper, concurrency is a hyper-parameter in addition to the buffer size. There was a problem hiding this comment. That's a good point and sorry for not combining Papaya's design. We should do 2 more things
|
||
|
|
||
|
|
@@ -81,11 +83,19 @@ def tictak_client_tasks(self, sampled_clients, num_clients_to_collect): | |
| return (sampled_clients, sampled_clients, completed_client_clock, | ||
| 1, completionTimes) | ||
|
|
||
| def save_last_param(self): | ||
| """ Save the last model parameters | ||
| """ | ||
| self.last_gradient_weights = [ | ||
| p.data.clone() for p in self.model.parameters()] | ||
| self.model_weights = copy.deepcopy(self.model.state_dict()) | ||
| self.weight_tensor_type = {p: self.model_weights[p].data.dtype \ | ||
| for p in self.model_weights} | ||
|
|
||
| def aggregate_client_weights(self, results): | ||
| """May aggregate client updates on the fly""" | ||
| """ | ||
| "PAPAYA: PRACTICAL, PRIVATE, AND SCALABLE FEDERATED LEARNING". MLSys, 2022 | ||
| """ | ||
| # Start to take the average of updates, and we do not keep updates to save memory | ||
| # Importance of each update is 1/#_of_participants * staleness | ||
|
|
@@ -95,54 +105,29 @@ def aggregate_client_weights(self, results): | |
| importance = 1. / math.sqrt(1 + client_staleness) | ||
|
|
||
| for p in results['update_weight']: | ||
| # Different to core/executor, update_weight here is (train_model_weight - untrained) | ||
| param_weight = results['update_weight'][p] | ||
|
|
||
| if isinstance(param_weight, list): | ||
| param_weight = np.asarray(param_weight, dtype=np.float32) | ||
| param_weight = torch.from_numpy( | ||
| param_weight).to(device=self.device) | ||
|
|
||
| if self.model_weights[p].data.dtype in ( | ||
| torch.float, torch.double, torch.half, | ||
| torch.bfloat16, torch.chalf, torch.cfloat, torch.cdouble | ||
| ): | ||
| # Only assign importance to floats (trainable variables) | ||
| self.model_weights[p].data += param_weight * importance | ||
| else: | ||
| # Non-floats (e.g., batches), no need to aggregate but need to track | ||
| self.model_weights[p].data += param_weight | ||
|
|
||
| if self.model_in_update == self.async_buffer_size: | ||
| logging.info("Calibrating tensor type") | ||
| for p in self.model_weights: | ||
| d_type = self.weight_tensor_type[p] | ||
| self.model_weights[p].data = (self.model_weights[p].data/float(self.async_buffer_size)).to(dtype=d_type) | ||
|
||
|
|
||
| def round_completion_handler(self): | ||
| self.global_virtual_clock = self.round_stamp[-1] | ||
|
|
@@ -173,7 +158,7 @@ def round_completion_handler(self): | |
| self.sampled_participants, len(self.sampled_participants)) | ||
|
|
||
| logging.info(f"{len(clientsToRun)} clients with constant arrival following the order: {clientsToRun}") | ||
| logging.info(f"====Register {len(clientsToRun)} to queue") | ||
| # Issue requests to the resource manager; Tasks ordered by the completion time | ||
| self.resource_manager.register_tasks(clientsToRun) | ||
| self.virtual_client_clock.update(virtual_client_clock) | ||
|
|
@@ -192,10 +177,12 @@ def round_completion_handler(self): | |
| self.test_result_accumulator = [] | ||
| self.stats_util_accumulator = [] | ||
| self.client_training_results = [] | ||
| self.loss_accumulator = [] | ||
|
|
||
| if self.round >= self.args.rounds: | ||
| self.broadcast_aggregator_events(commons.SHUT_DOWN) | ||
| elif self.round % self.args.eval_interval == 0: | ||
| self.test_model = copy.deepcopy(self.model) | ||
| self.broadcast_aggregator_events(commons.UPDATE_MODEL) | ||
| self.broadcast_aggregator_events(commons.MODEL_TEST) | ||
| else: | ||
|
|
@@ -206,15 +193,38 @@ def find_latest_model(self, start_time): | |
| for i, time_stamp in enumerate(reversed(self.round_stamp)): | ||
| if start_time >= time_stamp: | ||
| return len(self.round_stamp) - i | ||
| return 1 | ||
|
|
||
| def get_test_config(self, client_id): | ||
| """FL model testing on clients, developers can further define personalized client config here. | ||
|
|
||
| Args: | ||
| client_id (int): The client id. | ||
|
|
||
| Returns: | ||
| dictionary: The testing config for new task. | ||
|
|
||
| """ | ||
| # Get the straggler round-id | ||
| client_tasks = self.resource_manager.client_run_queue | ||
| current_pending_length = min( | ||
| self.resource_manager.client_run_queue_idx, len(client_tasks)-1) | ||
|
|
||
| current_pending_clients = client_tasks[current_pending_length:] | ||
| straggler_round = 1e10 | ||
| for client in current_pending_clients: | ||
| straggler_round = min( | ||
| self.find_latest_model(self.client_start_time[client]), straggler_round) | ||
|
|
||
| return {'client_id': client_id, 'straggler_round': straggler_round, 'test_model': self.test_model} | ||
|
|
||
| def get_client_conf(self, clientId): | ||
| """Training configurations that will be applied on clients""" | ||
| start_time = self.client_start_time[clientId] | ||
| model_id = self.find_latest_model(start_time) | ||
| self.client_model_version[clientId] = model_id | ||
| end_time = self.client_round_duration[clientId] + start_time | ||
| logging.info(f"Client {clientId} train on model {model_id} during {int(start_time)}-{int(end_time)}") | ||
|
|
||
| conf = { | ||
| 'learning_rate': self.args.learning_rate, | ||
|
|
@@ -227,17 +237,17 @@ def create_client_task(self, executorId): | |
|
|
||
| next_clientId = self.resource_manager.get_next_task(executorId) | ||
| train_config = None | ||
| model_version = None | ||
|
|
||
| if next_clientId != None: | ||
| config = self.get_client_conf(next_clientId) | ||
| model_version = self.find_latest_model(self.client_start_time[next_clientId]) | ||
| train_config = {'client_id': next_clientId, 'task_config': config} | ||
| return train_config, model_version | ||
|
|
||
| def CLIENT_EXECUTE_COMPLETION(self, request, context): | ||
| """FL clients complete the execution task. | ||
|
|
||
| Args: | ||
| request (CompleteRequest): Complete request info from executor. | ||
|
|
||
|
|
@@ -249,26 +259,26 @@ def CLIENT_EXECUTE_COMPLETION(self, request, context): | |
| executor_id, client_id, event = request.executor_id, request.client_id, request.event | ||
| execution_status, execution_msg = request.status, request.msg | ||
| meta_result, data_result = request.meta_result, request.data_result | ||
|
|
||
| if event == commons.CLIENT_TRAIN: | ||
| # Training results may be uploaded in CLIENT_EXECUTE_RESULT request later, | ||
| # so we need to specify whether to ask client to do so (in case of straggler/timeout in real FL). | ||
| if execution_status is False: | ||
| logging.error(f"Executor {executor_id} fails to run client {client_id}, due to {execution_msg}") | ||
|
|
||
| elif event in (commons.MODEL_TEST, commons.UPLOAD_MODEL): | ||
| self.add_event_handler( | ||
| executor_id, event, meta_result, data_result) | ||
| else: | ||
| logging.error(f"Received undefined event {event} from client {client_id}") | ||
|
|
||
| if self.resource_manager.has_next_task(executor_id): | ||
| # NOTE: we do not pop the train immediately in simulation mode, | ||
| # since the executor may run multiple clients | ||
| if commons.CLIENT_TRAIN not in self.individual_client_events[executor_id]: | ||
| self.individual_client_events[executor_id].append( | ||
| commons.CLIENT_TRAIN) | ||
|
|
||
| return self.CLIENT_PING(request, context) | ||
|
|
||
| def log_train_result(self, avg_loss): | ||
|
|
@@ -304,7 +314,7 @@ def event_monitor(self): | |
| if current_event == commons.UPLOAD_MODEL: | ||
| self.client_completion_handler( | ||
| self.deserialize_response(data)) | ||
| if self.model_in_update == self.async_buffer_size: | ||
| clientID = self.deserialize_response(data)['clientId'] | ||
| self.round_stamp.append( | ||
| self.client_round_duration[clientID] + self.client_start_time[clientID]) | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,64 @@ | ||
| import copy | ||
| import logging | ||
| import math | ||
|
|
||
| import torch | ||
| from torch.autograd import Variable | ||
|
|
||
| from fedscale.core.execution.client import Client | ||
| from fedscale.core.execution.optimizers import ClientOptimizer | ||
| from fedscale.dataloaders.nlp import mask_tokens | ||
|
|
||
|
|
||
| class Client(Client): | ||
| """Basic client component in Federated Learning""" | ||
|
|
||
| def train(self, client_data, model, conf): | ||
|
|
||
| clientId = conf.clientId | ||
| logging.info(f"Start to train (CLIENT: {clientId}) ...") | ||
| tokenizer, device = conf.tokenizer, conf.device | ||
|
|
||
| model = model.to(device=device) | ||
| model.train() | ||
|
|
||
| trained_unique_samples = min( | ||
| len(client_data.dataset), conf.local_steps * conf.batch_size) | ||
|
|
||
| self.global_model = None | ||
| if conf.gradient_policy == 'fed-prox': | ||
| # could be move to optimizer | ||
| self.global_model = [param.data.clone() for param in model.parameters()] | ||
|
|
||
| prev_model_dict = copy.deepcopy(model.state_dict()) | ||
| optimizer = self.get_optimizer(model, conf) | ||
| criterion = self.get_criterion(conf) | ||
| error_type = None | ||
|
|
||
| # TODO: One may hope to run fixed number of epochs, instead of iterations | ||
| while self.completed_steps < conf.local_steps: | ||
| try: | ||
| self.train_step(client_data, conf, model, optimizer, criterion) | ||
| except Exception as ex: | ||
| error_type = ex | ||
| break | ||
|
|
||
| state_dicts = model.state_dict() | ||
| # In async, we need the delta_weight only | ||
| model_param = {p: (state_dicts[p] - prev_model_dict[p]).data.cpu().numpy() | ||
| for p in state_dicts} | ||
| results = {'clientId': clientId, 'moving_loss': self.epoch_train_loss, | ||
| 'trained_size': self.completed_steps*conf.batch_size, | ||
| 'success': self.completed_steps == conf.batch_size} | ||
| results['utility'] = math.sqrt( | ||
| self.loss_squre)*float(trained_unique_samples) | ||
|
|
||
| if error_type is None: | ||
| logging.info(f"Training of (CLIENT: {clientId}) completes, {results}") | ||
| else: | ||
| logging.info(f"Training of (CLIENT: {clientId}) failed as {error_type}") | ||
|
|
||
| results['update_weight'] = model_param | ||
| results['wall_duration'] = 0 | ||
|
|
||
| return results |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The comment for this param might need to be updated for async. How do we decide what to use for num_participants since there's no notion of rounds in async?