Deep Network with Batch Normalization Training Example [Single Thread] [Multi Thread]
General architecture of this Network:
input 640x640x3 -> convolutional layer with 7x7x64 kernel dimensions, stride = 3,leaky relu, max pooling 2x2 dimensions, stride = 2, local response normalization -> convolutional layer with 3x3x192 kernel dimensions, stride = 1, leaky relu, max pooling 2x2 dimensions, stride = 2, local response normalization -> residual layer with 4 convolutional layers: 1° convolutional layer with 1x1x128 kernel dimensions, stride = 1, leaky relu, local response normalization, 2° convolutional layer with 3x3x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 3° convolutional layer with 1x1x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 4° convolutional layer with 3x3x192 kernel dimensions, stride = 1, leaky relu, padding = 2 -> batch normalization -> max pooling 2x2 dimensions, stride = 2 -> residual layer with 4 convolutional layers: 1° convolutional layer with 1x1x128 kernel dimensions, stride = 1, leaky relu, local response normalization, 2° convolutional layer with 3x3x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 3° convolutional layer with 1x1x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 4° convolutional layer with 3x3x192 kernel dimensions, stride = 1, leaky relu, padding = 2 -> batch normalization -> max pooling 2x2 dimensions, stride = 2 -> residual layer with 4 convolutional layers: 1° convolutional layer with 1x1x128 kernel dimensions, stride = 1, leaky relu, local response normalization, 2° convolutional layer with 3x3x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 3° convolutional layer with 1x1x256 kernel dimensions, stride = 1, leaky relu, local response normalization, 4° convolutional layer with 3x3x192 kernel dimensions, stride = 1, leaky relu, padding = 2 -> batch normalization -> max pooling 2x2 dimensions, stride = 2 -> fully connected layer with 1024 output neurons, leaky relu -> fully connected layer with 1024 output neurons, leaky relu
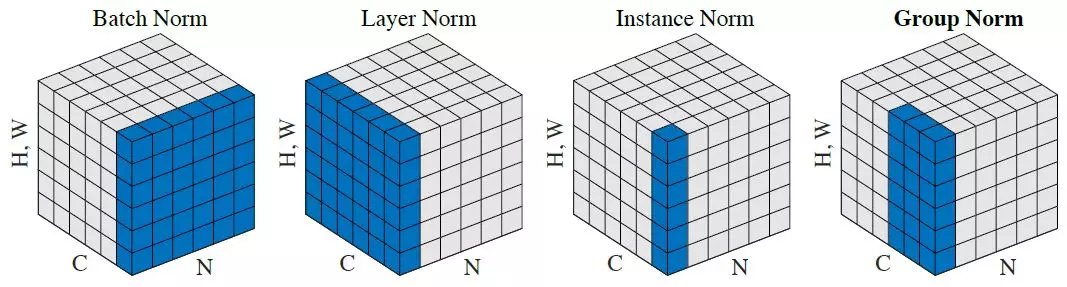
In this examples the batch normalization is used not for feature map of each convoluted layer, but for the entire convoluted output, you can always do the correct batch normalization per feature map adding a batch normalized layer per each one and passing to the batch normalization feed forward function the correct output. the batch normalization according to your input can be used also as grouped normalization, instance normalization and layer normalization, here the differences:
#include <stdio.h>
#include <stdlib.h>
#include "llab.h"
int main(){
/* First model with 6 convolutional layers* */
/* Second model with 4 convolutional layers grouped up in a residual layer */
/* Third model with 4 convolutional layers grouped up in a residual layer */
int output = 1024; //not chosen yet
int input_channels = 3, input_rows = 640, input_cols = 640;
int batch_size = 2,n_instances = 10;
float lr, b1_adam1 = BETA1_ADAM, b2_adam1 = BETA2_ADAM;
float b1_adam2 = BETA1_ADAM, b2_adam2 = BETA2_ADAM;
float b1_adam3 = BETA1_ADAM, b2_adam3 = BETA2_ADAM;
float b1_adam4 = BETA1_ADAM, b2_adam4 = BETA2_ADAM;
float b1_adam5 = BETA1_ADAM, b2_adam5 = BETA2_ADAM;
float b1_adam6 = BETA1_ADAM, b2_adam6 = BETA2_ADAM;
float b1_adam7 = BETA1_ADAM, b2_adam7 = BETA2_ADAM;
int i,j;
float** input = (float**)malloc(sizeof(float*)*n_instances);
for(i = 0; i < n_instances; i++){
input[i] = (float*)calloc(input_channels*input_rows*input_cols,sizeof(float));
}
cl** c1 = (cl**)malloc(sizeof(cl*)*2);
cl** c2 = (cl**)malloc(sizeof(cl*)*4);
cl** c3 = (cl**)malloc(sizeof(cl*)*4);
cl** c4 = (cl**)malloc(sizeof(cl*)*4);
rl** r1 = (rl**)malloc(sizeof(rl*));
rl** r2 = (rl**)malloc(sizeof(rl*));
rl** r3 = (rl**)malloc(sizeof(rl*));
fcl** f1 = (fcl**)malloc(sizeof(fcl*)*2);
/* batch normalization and max-pooling after the 3 residual layers*/
bn** b1 = (bn**)malloc(sizeof(bn*)*3);
cl** c5 = (cl**)malloc(sizeof(cl*));
cl** c6 = (cl**)malloc(sizeof(cl*));
cl** c7 = (cl**)malloc(sizeof(cl*));
// First 2 convolutional layers
c1[0] = convolutional(3,640,640,7,7,64,3,3,0,0,2,2,0,0,2,2,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,MAX_POOLING,0,CONVOLUTION);
c1[1] = convolutional(64,106,106,3,3,192,1,1,0,0,2,2,0,0,2,2,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,MAX_POOLING,1,CONVOLUTION);
// 4 convolutional layer of first residual layer
c2[0] = convolutional(192,52,52,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c2[1] = convolutional(128,52,52,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c2[2] = convolutional(256,50,50,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
c2[3] = convolutional(256,50,50,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,5,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
// 4 convolutional layer of second residual layer
c3[0] = convolutional(192,26,26,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,1,CONVOLUTION);
c3[1] = convolutional(128,26,26,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c3[2] = convolutional(256,24,24,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c3[3] = convolutional(256,24,24,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
// 4 convolutional layer of third residual layer
c4[0] = convolutional(192,13,13,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,1,CONVOLUTION);
c4[1] = convolutional(128,13,13,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c4[2] = convolutional(256,11,11,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c4[3] = convolutional(256,11,11,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
//192x6x6 total output at this moment
// 2 terminal fully connected layers
f1[0] = fully_connected(192*6*6,1024,1,NO_DROPOUT,LEAKY_RELU,0);
f1[1] = fully_connected(1024,1024,2,NO_DROPOUT,LEAKY_RELU,0);
// initialize the 3 residual layers
r1[0] = residual(192,52,52,4,c2);
r2[0] = residual(192,26,26,4,c3);
r3[0] = residual(192,13,13,4,c4);
// use the leaky relu function as final activation function after each residual layer
r1[0]->cl_output->activation_flag = LEAKY_RELU;
r2[0]->cl_output->activation_flag = LEAKY_RELU;
r3[0]->cl_output->activation_flag = LEAKY_RELU;
// batch normalization and max pooling layers
b1[0] = batch_normalization(batch_size,192*52*52,0,NO_ACTIVATION);
b1[1] = batch_normalization(batch_size,192*26*26,1,NO_ACTIVATION);
b1[2] = batch_normalization(batch_size,192*13*13,2,NO_ACTIVATION);
c5[0] = convolutional(192,52,52,1,1,192,1,1,0,0,2,2,0,0,2,2,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
c6[0] = convolutional(192,26,26,1,1,192,1,1,0,0,2,2,0,0,2,2,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
c7[0] = convolutional(192,13,13,1,1,192,1,1,0,0,2,2,0,0,3,3,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
// create the networks, the temporary networks (es temp_m1) are used to handle the sum of the derivatives across the mini batches
model* m1 = network(6,1,2,0,r1,c1,NULL);
model* temp_m1 = copy_model(m1);
model* m2 = network(5,1,1,0,r2,c5,NULL);
model* temp_m2 = copy_model(m2);
model* m3 = network(5,1,1,0,r3,c6,NULL);
model* temp_m3 = copy_model(m3);
model* m4 = network(3,0,1,2,NULL,c7,f1);
model* temp_m4 = copy_model(m4);
bmodel* bm = batch_network(3,0,0,0,3,NULL,NULL,NULL,b1);
// the mini batch models
model** batch_m1 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m2 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m3 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m4 = (model**)malloc(sizeof(model*)*batch_size);
for(i = 0; i < batch_size; i++){
batch_m1[i] = copy_model(m1);
batch_m2[i] = copy_model(m2);
batch_m3[i] = copy_model(m3);
batch_m4[i] = copy_model(m4);
}
// input vectors after the first second and third residual layer
float** input_vectors1 = (float**)malloc(sizeof(float*)*batch_size);
float** input_vectors2 = (float**)malloc(sizeof(float*)*batch_size);
float** input_vectors3 = (float**)malloc(sizeof(float*)*batch_size);
for(i = 0; i < batch_size; i++){
input_vectors1[i] = batch_m1[i]->rls[0]->cl_output->post_activation;
input_vectors2[i] = batch_m2[i]->rls[0]->cl_output->post_activation;
input_vectors3[i] = batch_m3[i]->rls[0]->cl_output->post_activation;
}
/* Training */
for(i = 0; i < n_instances/batch_size; i++){
// Feed forward
for(j = 0; j < batch_size; j++){
model_tensor_input_ff(batch_m1[j],input_channels, input_rows, input_cols, input[i*batch_size+j]);
}
batch_normalization_feed_forward(batch_size, input_vectors1,b1[0]->temp_vectors, b1[0]->vector_dim, b1[0]->gamma, b1[0]->beta, b1[0]->mean, b1[0]->var, b1[0]->outputs,b1[0]->epsilon);
for(j = 0; j < batch_size; j++){
model_tensor_input_ff(batch_m2[j],batch_m2[j]->cls[0]->channels,batch_m2[j]->cls[0]->input_rows,batch_m2[j]->cls[0]->input_cols,b1[0]->outputs[j]);
}
batch_normalization_feed_forward(batch_size, input_vectors2,b1[1]->temp_vectors, b1[1]->vector_dim, b1[1]->gamma, b1[1]->beta, b1[1]->mean, b1[1]->var, b1[1]->outputs,b1[1]->epsilon);
for(j = 0; j < batch_size; j++){
model_tensor_input_ff(batch_m3[j],batch_m3[j]->cls[0]->channels,batch_m3[j]->cls[0]->input_rows,batch_m3[j]->cls[0]->input_cols,b1[1]->outputs[j]);
}
batch_normalization_feed_forward(batch_size, input_vectors3,b1[2]->temp_vectors, b1[2]->vector_dim, b1[2]->gamma, b1[2]->beta, b1[2]->mean, b1[2]->var, b1[2]->outputs,b1[2]->epsilon);
for(j = 0; j < batch_size; j++){
model_tensor_input_ff(batch_m4[j],batch_m4[j]->cls[0]->channels,batch_m4[j]->cls[0]->input_rows,batch_m4[j]->cls[0]->input_cols,b1[2]->outputs[j]);
}
// Set the errors
float** error = (float**)malloc(sizeof(float*)*batch_size);
for(j = 0; j < batch_size; j++){
error[j] = (float*)calloc(batch_m4[0]->fcls[0]->output,sizeof(float));
}
// BackPropagation
for(j = 0; j < batch_size; j++){
error[j] = model_tensor_input_bp(batch_m4[j],batch_m4[j]->cls[0]->channels,batch_m4[j]->cls[0]->input_rows,batch_m4[j]->cls[0]->input_cols,b1[2]->outputs[j], error[j], batch_m4[j]->fcls[1]->output);
}
batch_normalization_back_prop(batch_size,input_vectors3,b1[2]->temp_vectors, b1[2]->vector_dim, b1[2]->gamma, b1[2]->beta, b1[2]->mean, b1[2]->var,error,b1[2]->d_gamma, b1[2]->d_beta,b1[2]->error2, b1[2]->temp1,b1[2]->temp2, b1[2]->epsilon);
for(j = 0; j < batch_size; j++){
// Computing derivative leaky relu
derivative_leaky_relu_array(batch_m3[j]->rls[0]->cl_output->pre_activation,batch_m3[j]->rls[0]->cl_output->temp3,b1[2]->vector_dim);
dot1D(batch_m3[j]->rls[0]->cl_output->temp3,b1[2]->error2[j],batch_m3[j]->rls[0]->cl_output->temp,b1[2]->vector_dim);
error[j] = model_tensor_input_bp(batch_m3[j],batch_m3[j]->cls[0]->channels,batch_m3[j]->cls[0]->input_rows,batch_m3[j]->cls[0]->input_cols,b1[1]->outputs[j], batch_m3[j]->rls[0]->cl_output->temp, batch_m3[j]->rls[0]->cl_output->n_kernels*batch_m3[j]->rls[0]->cl_output->rows1*batch_m3[j]->rls[0]->cl_output->cols1);
}
batch_normalization_back_prop(batch_size,input_vectors2,b1[1]->temp_vectors, b1[1]->vector_dim, b1[1]->gamma, b1[1]->beta, b1[1]->mean, b1[1]->var,error,b1[1]->d_gamma, b1[1]->d_beta,b1[1]->error2, b1[1]->temp1,b1[1]->temp2, b1[1]->epsilon);
for(j = 0; j < batch_size; j++){
// Computing derivative leaky relu
derivative_leaky_relu_array(batch_m2[j]->rls[0]->cl_output->pre_activation,batch_m2[j]->rls[0]->cl_output->temp3,b1[1]->vector_dim);
dot1D(batch_m2[j]->rls[0]->cl_output->temp3,b1[1]->error2[j],batch_m2[j]->rls[0]->cl_output->temp,b1[1]->vector_dim);
error[j] = model_tensor_input_bp(batch_m2[j],batch_m2[j]->cls[0]->channels,batch_m2[j]->cls[0]->input_rows,batch_m2[j]->cls[0]->input_cols,b1[0]->outputs[j], batch_m2[j]->rls[0]->cl_output->temp, batch_m2[j]->rls[0]->cl_output->n_kernels*batch_m2[j]->rls[0]->cl_output->rows1*batch_m2[j]->rls[0]->cl_output->cols1);
}
batch_normalization_back_prop(batch_size,input_vectors1,b1[0]->temp_vectors, b1[0]->vector_dim, b1[0]->gamma, b1[0]->beta, b1[0]->mean, b1[0]->var,error,b1[0]->d_gamma, b1[0]->d_beta,b1[0]->error2, b1[0]->temp1,b1[0]->temp2, b1[0]->epsilon);
for(j = 0; j < batch_size; j++){
// Computing derivative leaky relu
derivative_leaky_relu_array(batch_m1[j]->rls[0]->cl_output->pre_activation,batch_m1[j]->rls[0]->cl_output->temp3,b1[0]->vector_dim);
dot1D(batch_m1[j]->rls[0]->cl_output->temp3,b1[0]->error2[j],batch_m1[j]->rls[0]->cl_output->temp,b1[0]->vector_dim);
error[j] = model_tensor_input_bp(batch_m1[j],input_channels,input_rows,input_cols,input[i*batch_size+j], batch_m1[j]->rls[0]->cl_output->temp, batch_m1[j]->rls[0]->cl_output->n_kernels*batch_m1[j]->rls[0]->cl_output->rows1*batch_m1[j]->rls[0]->cl_output->cols1);
}
for(j = 0; j < batch_size; j++){
sum_model_partial_derivatives(temp_m1,batch_m1[j],temp_m1);
sum_model_partial_derivatives(temp_m2,batch_m2[j],temp_m2);
sum_model_partial_derivatives(temp_m3,batch_m3[j],temp_m3);
sum_model_partial_derivatives(temp_m4,batch_m4[j],temp_m4);
}
update_bmodel(bm,lr,0.9,batch_size,ADAM,&b1_adam5,&b2_adam5,NO_REGULARIZATION,0,0);
update_model(temp_m1,lr,0.9,batch_size,ADAM,&b1_adam1,&b2_adam1,NO_REGULARIZATION,0,0);
update_model(temp_m2,lr,0.9,batch_size,ADAM,&b1_adam2,&b2_adam2,NO_REGULARIZATION,0,0);
update_model(temp_m3,lr,0.9,batch_size,ADAM,&b1_adam3,&b2_adam3,NO_REGULARIZATION,0,0);
update_model(temp_m4,lr,0.9,batch_size,ADAM,&b1_adam4,&b2_adam4,NO_REGULARIZATION,0,0);
reset_bmodel(bm);
reset_model(temp_m1);
reset_model(temp_m2);
reset_model(temp_m3);
reset_model(temp_m4);
for(j = 0; j < batch_size; j++){
paste_model(temp_m1,batch_m1[j]);
paste_model(temp_m2,batch_m2[j]);
paste_model(temp_m3,batch_m3[j]);
paste_model(temp_m4,batch_m4[j]);
}
}
for(i = 0; i < n_instances; i++){
free(input[i]);
}
free(input);
free_model(temp_m1);
free_model(temp_m2);
free_model(temp_m3);
free_model(temp_m4);
free_model(m1);
free_model(m2);
free_model(m3);
free_model(m4);
free_bmodel(bm);
for(i = 0; i < batch_size; i++){
free_model(batch_m1[i]);
free_model(batch_m2[i]);
free_model(batch_m3[i]);
free_model(batch_m4[i]);
}
free(batch_m1);
free(batch_m2);
free(batch_m3);
free(batch_m4);
free(input_vectors1);
free(input_vectors2);
free(input_vectors3);
// The errors are not freed
}
#include <stdio.h>
#include <stdlib.h>
#include "llab.h"
int main(){
/* First model with 6 convolutional layers* */
/* Second model with 4 convolutional layers grouped up in a residual layer */
/* Third model with 4 convolutional layers grouped up in a residual layer */
srand(time(NULL));
int output = 183;
int input_channels = 3, input_rows = 640, input_cols = 640;
int batch_size = 3,n_instances = 10;
float lr, b1_adam1 = BETA1_ADAM, b2_adam1 = BETA2_ADAM;
float b1_adam2 = BETA1_ADAM, b2_adam2 = BETA2_ADAM;
float b1_adam3 = BETA1_ADAM, b2_adam3 = BETA2_ADAM;
float b1_adam4 = BETA1_ADAM, b2_adam4 = BETA2_ADAM;
float b1_adam5 = BETA1_ADAM, b2_adam5 = BETA2_ADAM;
float b1_adam6 = BETA1_ADAM, b2_adam6 = BETA2_ADAM;
float b1_adam7 = BETA1_ADAM, b2_adam7 = BETA2_ADAM;
int i,j;
float** input = (float**)malloc(sizeof(float*)*n_instances);
for(i = 0; i < n_instances; i++){
input[i] = (float*)calloc(input_channels*input_rows*input_cols,sizeof(float));
}
cl** c1 = (cl**)malloc(sizeof(cl*)*2);
cl** c2 = (cl**)malloc(sizeof(cl*)*4);
cl** c3 = (cl**)malloc(sizeof(cl*)*4);
cl** c4 = (cl**)malloc(sizeof(cl*)*4);
rl** r1 = (rl**)malloc(sizeof(rl*));
rl** r2 = (rl**)malloc(sizeof(rl*));
rl** r3 = (rl**)malloc(sizeof(rl*));
fcl** f1 = (fcl**)malloc(sizeof(fcl*)*2);
/* batch normalization and max-pooling after the 3 residual layers*/
bn** b1 = (bn**)malloc(sizeof(bn*)*3);
cl** c5 = (cl**)malloc(sizeof(cl*));
cl** c6 = (cl**)malloc(sizeof(cl*));
cl** c7 = (cl**)malloc(sizeof(cl*));
// First 2 convolutional layers
c1[0] = convolutional(3,640,640,7,7,64,3,3,0,0,2,2,0,0,2,2,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,MAX_POOLING,0,CONVOLUTION);
c1[1] = convolutional(64,106,106,3,3,192,1,1,0,0,2,2,0,0,2,2,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,MAX_POOLING,1,CONVOLUTION);
// 4 convolutional layer of first residual layer
c2[0] = convolutional(192,52,52,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c2[1] = convolutional(128,52,52,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c2[2] = convolutional(256,50,50,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
c2[3] = convolutional(256,50,50,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,5,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
// 4 convolutional layer of second residual layer
c3[0] = convolutional(192,26,26,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,1,CONVOLUTION);
c3[1] = convolutional(128,26,26,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c3[2] = convolutional(256,24,24,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c3[3] = convolutional(256,24,24,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
// 4 convolutional layer of third residual layer
c4[0] = convolutional(192,13,13,1,1,128,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,1,CONVOLUTION);
c4[1] = convolutional(128,13,13,3,3,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,2,CONVOLUTION);
c4[2] = convolutional(256,11,11,1,1,256,1,1,0,0,1,1,0,0,0,0,LOCAL_RESPONSE_NORMALIZATION,LEAKY_RELU,NO_POOLING,3,CONVOLUTION);
c4[3] = convolutional(256,11,11,3,3,192,1,1,2,2,1,1,0,0,0,0,NO_NORMALIZATION,LEAKY_RELU,NO_POOLING,4,CONVOLUTION);
//batch normalization
//max pooling 2x2 s = 2
//192x6x6 total output at this moment
// 2 terminal fully connected layers
f1[0] = fully_connected(192*6*6,4096,1,NO_DROPOUT,LEAKY_RELU,0);
f1[1] = fully_connected(4096,output,2,NO_DROPOUT,LEAKY_RELU,0);
// initialize the 3 residual layers
r1[0] = residual(192,52,52,4,c2);
r2[0] = residual(192,26,26,4,c3);
r3[0] = residual(192,13,13,4,c4);
// use the leaky relu function as final activation function after each residual layer
r1[0]->cl_output->activation_flag = LEAKY_RELU;
r2[0]->cl_output->activation_flag = LEAKY_RELU;
r3[0]->cl_output->activation_flag = LEAKY_RELU;
// batch normalization and max pooling layers
b1[0] = batch_normalization(batch_size,192*52*52,0,NO_ACTIVATION);
b1[1] = batch_normalization(batch_size,192*26*26,1,NO_ACTIVATION);
b1[2] = batch_normalization(batch_size,192*13*13,2,NO_ACTIVATION);
c5[0] = convolutional(192,52,52,1,1,192,1,1,0,0,2,2,0,0,2,2,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
c6[0] = convolutional(192,26,26,1,1,192,1,1,0,0,2,2,0,0,2,2,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
c7[0] = convolutional(192,13,13,1,1,192,1,1,0,0,2,2,0,0,3,3,NO_NORMALIZATION,NO_ACTIVATION,MAX_POOLING,0,NO_CONVOLUTION);
// create the networks, the temporary networks (es temp_m1) are used to handle the sum of the derivatives across the mini batches
model* m1 = network(6,1,2,0,r1,c1,NULL);
model* temp_m1 = copy_model(m1);
model* m2 = network(5,1,1,0,r2,c5,NULL);
model* temp_m2 = copy_model(m2);
model* m3 = network(5,1,1,0,r3,c6,NULL);
model* temp_m3 = copy_model(m3);
model* m4 = network(3,0,1,2,NULL,c7,f1);
model* temp_m4 = copy_model(m4);
bmodel* bm = batch_network(3,0,0,0,3,NULL,NULL,NULL,b1);
// the mini batch models
model** batch_m1 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m2 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m3 = (model**)malloc(sizeof(model*)*batch_size);
model** batch_m4 = (model**)malloc(sizeof(model*)*batch_size);
for(i = 0; i < batch_size; i++){
batch_m1[i] = copy_model(m1);
batch_m2[i] = copy_model(m2);
batch_m3[i] = copy_model(m3);
batch_m4[i] = copy_model(m4);
}
// input vectors after the first second and third residual layer
float** input_vectors1 = (float**)malloc(sizeof(float*)*batch_size);
float** input_vectors2 = (float**)malloc(sizeof(float*)*batch_size);
float** input_vectors3 = (float**)malloc(sizeof(float*)*batch_size);
for(i = 0; i < batch_size; i++){
input_vectors1[i] = batch_m1[i]->rls[0]->cl_output->post_activation;
input_vectors2[i] = batch_m2[i]->rls[0]->cl_output->post_activation;
input_vectors3[i] = batch_m3[i]->rls[0]->cl_output->post_activation;
}
int threads = 2;
/* Training */
for(i = 0; i < n_instances/batch_size; i++){
// Feed forward
model_tensor_input_ff_multicore(batch_m1,input_channels,input_rows,input_cols,&input[i], batch_size,threads);
batch_normalization_feed_forward(batch_size, input_vectors1,b1[0]->temp_vectors, b1[0]->vector_dim, b1[0]->gamma, b1[0]->beta, b1[0]->mean, b1[0]->var, b1[0]->outputs,b1[0]->epsilon);
model_tensor_input_ff_multicore(batch_m2,batch_m2[0]->cls[0]->channels,batch_m2[0]->cls[0]->input_rows,batch_m2[0]->cls[0]->input_cols,b1[0]->outputs, batch_size,threads);
batch_normalization_feed_forward(batch_size, input_vectors2,b1[1]->temp_vectors, b1[1]->vector_dim, b1[1]->gamma, b1[1]->beta, b1[1]->mean, b1[1]->var, b1[1]->outputs,b1[1]->epsilon);
model_tensor_input_ff_multicore(batch_m3,batch_m3[0]->cls[0]->channels,batch_m3[0]->cls[0]->input_rows,batch_m3[0]->cls[0]->input_cols,b1[1]->outputs, batch_size,threads);
batch_normalization_feed_forward(batch_size, input_vectors3,b1[2]->temp_vectors, b1[2]->vector_dim, b1[2]->gamma, b1[2]->beta, b1[2]->mean, b1[2]->var, b1[2]->outputs,b1[2]->epsilon);
model_tensor_input_ff_multicore(batch_m4,batch_m4[0]->cls[0]->channels,batch_m4[0]->cls[0]->input_rows,batch_m4[0]->cls[0]->input_cols,b1[2]->outputs, batch_size,threads);
// Set the errors
float** error = (float**)malloc(sizeof(float*)*batch_size);
for(j = 0; j < batch_size; j++){
error[j] = (float*)calloc(output,sizeof(float));
}
// BackPropagation
model_tensor_input_bp_multicore(batch_m4,batch_m4[0]->cls[0]->channels,batch_m4[0]->cls[0]->input_rows,batch_m4[0]->cls[0]->input_cols,b1[2]->outputs,batch_size,threads,error,output,error);
batch_normalization_back_prop(batch_size,input_vectors3,b1[2]->temp_vectors, b1[2]->vector_dim, b1[2]->gamma, b1[2]->beta, b1[2]->mean, b1[2]->var,error,b1[2]->d_gamma, b1[2]->d_beta,b1[2]->error2, b1[2]->temp1,b1[2]->temp2, b1[2]->epsilon);
for(j = 0; j < batch_size; j++){
// Computing derivative leaky relu
derivative_leaky_relu_array(batch_m3[j]->rls[0]->cl_output->pre_activation,batch_m3[j]->rls[0]->cl_output->temp3,b1[2]->vector_dim);
dot1D(batch_m3[j]->rls[0]->cl_output->temp3,b1[2]->error2[j],batch_m3[j]->rls[0]->cl_output->temp,b1[2]->vector_dim);
error[j] = batch_m3[j]->rls[0]->cl_output->temp;
}
j = 0;
model_tensor_input_bp_multicore(batch_m3,batch_m3[0]->cls[0]->channels,batch_m3[0]->cls[0]->input_rows,batch_m3[0]->cls[0]->input_cols,b1[1]->outputs,batch_size,threads,error,batch_m3[j]->rls[0]->cl_output->n_kernels*batch_m3[j]->rls[0]->cl_output->rows1*batch_m3[j]->rls[0]->cl_output->cols1,error);
batch_normalization_back_prop(batch_size,input_vectors2,b1[1]->temp_vectors, b1[1]->vector_dim, b1[1]->gamma, b1[1]->beta, b1[1]->mean, b1[1]->var,error,b1[1]->d_gamma, b1[1]->d_beta,b1[1]->error2, b1[1]->temp1,b1[1]->temp2, b1[1]->epsilon);
for(j = 0; j < batch_size; j++){
// Computing derivative leaky relu
derivative_leaky_relu_array(batch_m2[j]->rls[0]->cl_output->pre_activation,batch_m2[j]->rls[0]->cl_output->temp3,b1[1]->vector_dim);
dot1D(batch_m2[j]->rls[0]->cl_output->temp3,b1[1]->error2[j],batch_m2[j]->rls[0]->cl_output->temp,b1[1]->vector_dim);
error[j] = batch_m2[j]->rls[0]->cl_output->temp;
}
j = 0;
model_tensor_input_bp_multicore(batch_m2,batch_m2[0]->cls[0]->channels,batch_m2[0]->cls[0]->input_rows,batch_m2[0]->cls[0]->input_cols,b1[0]->outputs,batch_size,threads,error,batch_m2[j]->rls[0]->cl_output->n_kernels*batch_m2[j]->rls[0]->cl_output->rows1*batch_m2[j]->rls[0]->cl_output->cols1,error);
batch_normalization_back_prop(batch_size,input_vectors1,b1[0]->temp_vectors, b1[0]->vector_dim, b1[0]->gamma, b1[0]->beta, b1[0]->mean, b1[0]->var,error,b1[0]->d_gamma, b1[0]->d_beta,b1[0]->error2, b1[0]->temp1,b1[0]->temp2, b1[0]->epsilon);
for(j = 0; j < batch_size; j++){
derivative_leaky_relu_array(batch_m1[j]->rls[0]->cl_output->pre_activation,batch_m1[j]->rls[0]->cl_output->temp3,b1[0]->vector_dim);
dot1D(batch_m1[j]->rls[0]->cl_output->temp3,b1[0]->error2[j],batch_m1[j]->rls[0]->cl_output->temp,b1[0]->vector_dim);
error[j] = batch_m1[j]->rls[0]->cl_output->temp;
}
j = 0;
model_tensor_input_bp_multicore(batch_m1,input_channels,input_rows,input_cols,&input[i*batch_size],batch_size,threads,error,batch_m1[j]->rls[0]->cl_output->n_kernels*batch_m1[j]->rls[0]->cl_output->rows1*batch_m1[j]->rls[0]->cl_output->cols1,error);
for(j = 0; j < batch_size; j++){
sum_model_partial_derivatives(temp_m1,batch_m1[j],temp_m1);
sum_model_partial_derivatives(temp_m2,batch_m2[j],temp_m2);
sum_model_partial_derivatives(temp_m3,batch_m3[j],temp_m3);
sum_model_partial_derivatives(temp_m4,batch_m4[j],temp_m4);
}
update_bmodel(bm,lr,0.9,batch_size,ADAM,&b1_adam5,&b2_adam5,NO_REGULARIZATION,0,0);
update_model(temp_m1,lr,0.9,batch_size,ADAM,&b1_adam1,&b2_adam1,NO_REGULARIZATION,0,0);
update_model(temp_m2,lr,0.9,batch_size,ADAM,&b1_adam2,&b2_adam2,NO_REGULARIZATION,0,0);
update_model(temp_m3,lr,0.9,batch_size,ADAM,&b1_adam3,&b2_adam3,NO_REGULARIZATION,0,0);
update_model(temp_m4,lr,0.9,batch_size,ADAM,&b1_adam4,&b2_adam4,NO_REGULARIZATION,0,0);
reset_bmodel(bm);
reset_model(temp_m1);
reset_model(temp_m2);
reset_model(temp_m3);
reset_model(temp_m4);
for(j = 0; j < batch_size; j++){
paste_model(temp_m1,batch_m1[j]);
paste_model(temp_m2,batch_m2[j]);
paste_model(temp_m3,batch_m3[j]);
paste_model(temp_m4,batch_m4[j]);
}
}
for(i = 0; i < n_instances; i++){
free(input[i]);
}
free(input);
free_model(temp_m1);
free_model(temp_m2);
free_model(temp_m3);
free_model(temp_m4);
free_model(m1);
free_model(m2);
free_model(m3);
free_model(m4);
free_bmodel(bm);
for(i = 0; i < batch_size; i++){
free_model(batch_m1[i]);
free_model(batch_m2[i]);
free_model(batch_m3[i]);
free_model(batch_m4[i]);
}
free(batch_m1);
free(batch_m2);
free(batch_m3);
free(batch_m4);
free(input_vectors1);
free(input_vectors2);
free(input_vectors3);
// The errors are not freed
}