This project demonstrates a lightweight workflow for evaluating and improving documentation so it can be reliably used by AI agents — not just humans.
An example agent-readiness review flow that:
- Identifies where documentation breaks down for automated agents
- Rewrites instructions into clear, executable steps
- Validates the result with a simple, transparent scoring model
- Outputs a final status with concrete next actions
Example scenario: Validating a subscription cancellation workflow for autonomous agent execution.
Most documentation is written for humans and relies on:
- Screenshots
- Implicit navigation
- Assumed context
- Ambiguous language
These patterns cause agents to fail, loop, or require human intervention.
Agent-ready documentation:
- Reduces task failure rates and support escalations
- Enables reliable automation at scale
- Treats documentation as executable infrastructure, not just reference material
- Makes content reusable across both humans and AI systems
This reframes documentation as part of the system itself, not a passive artifact.
- Problem → solution comparison — Issues and fixes are shown clearly, not implied
- Severity signaling — Blockers, warnings, and ready states are visually distinct
- Progressive disclosure — Summary → detailed issues → fixes → final status
- Transparent scoring — Improvements are measurable and explainable (42 → 89 / 100)

End-to-end validation workflow from input to final status.
Error & recovery guidance — explains what went wrong and provides clear, actionable next steps to help users recover and continue.

Problems identified on the left, actionable fixes on the right.
Outcome clarity & next steps — communicates final status, measurable improvement, and clear actions so users know what to do next.

Final status with measurable improvement and next steps.
- A practical framework for reviewing documentation for agent readiness
- How small structural changes improve agent reliability
- How validation results can be communicated clearly and transparently
- What a realistic “completion state” looks like in internal tooling
This is a conceptual reference, not a production UI — intended for teams designing agent workflows, internal tools, or AI-assisted systems.
Beyond the prototype UI, this project includes a quality framework for evaluating and improving validator accuracy.
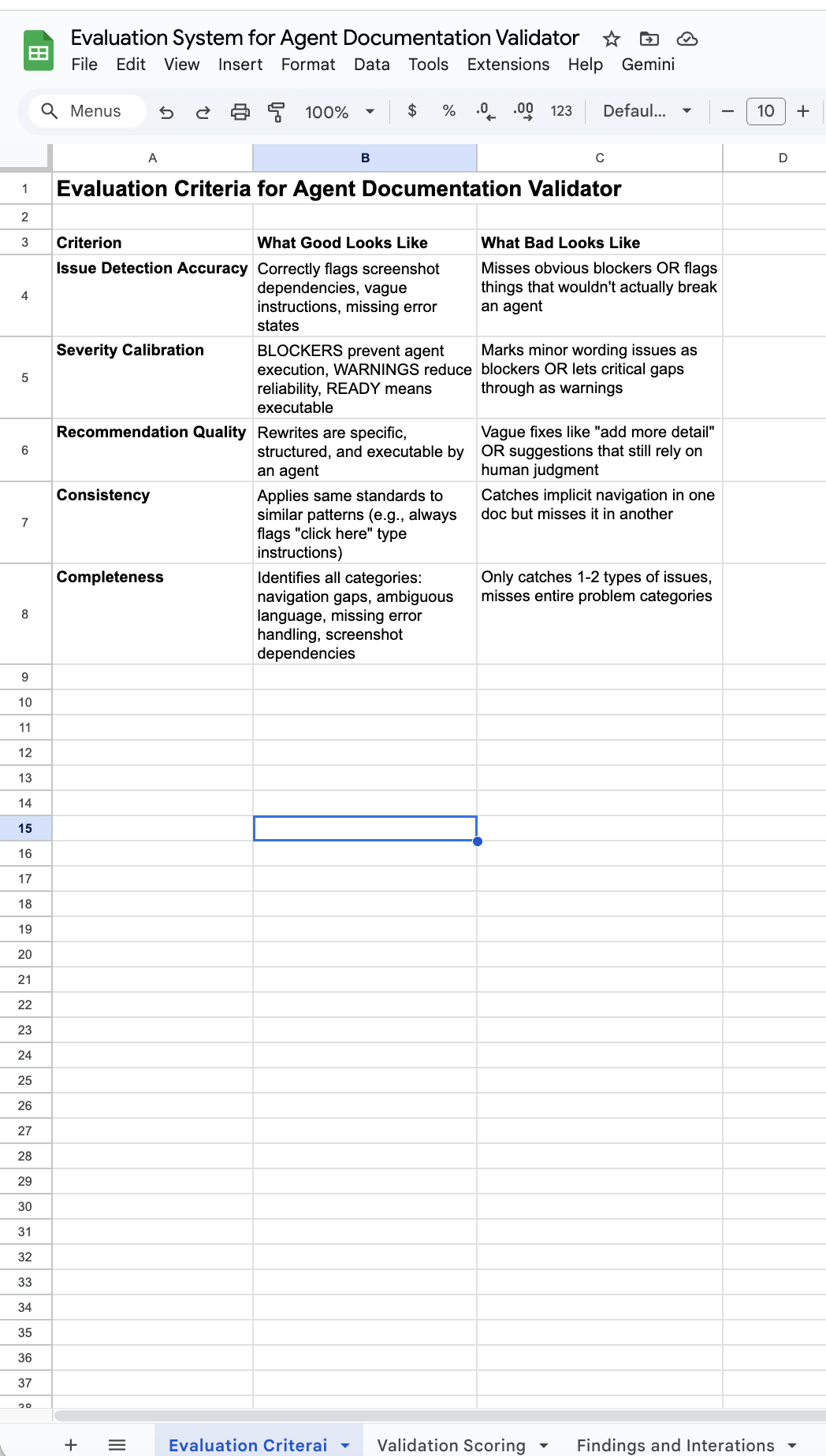
This snapshot shows the rubric used to judge whether documentation is executable by an AI agent.
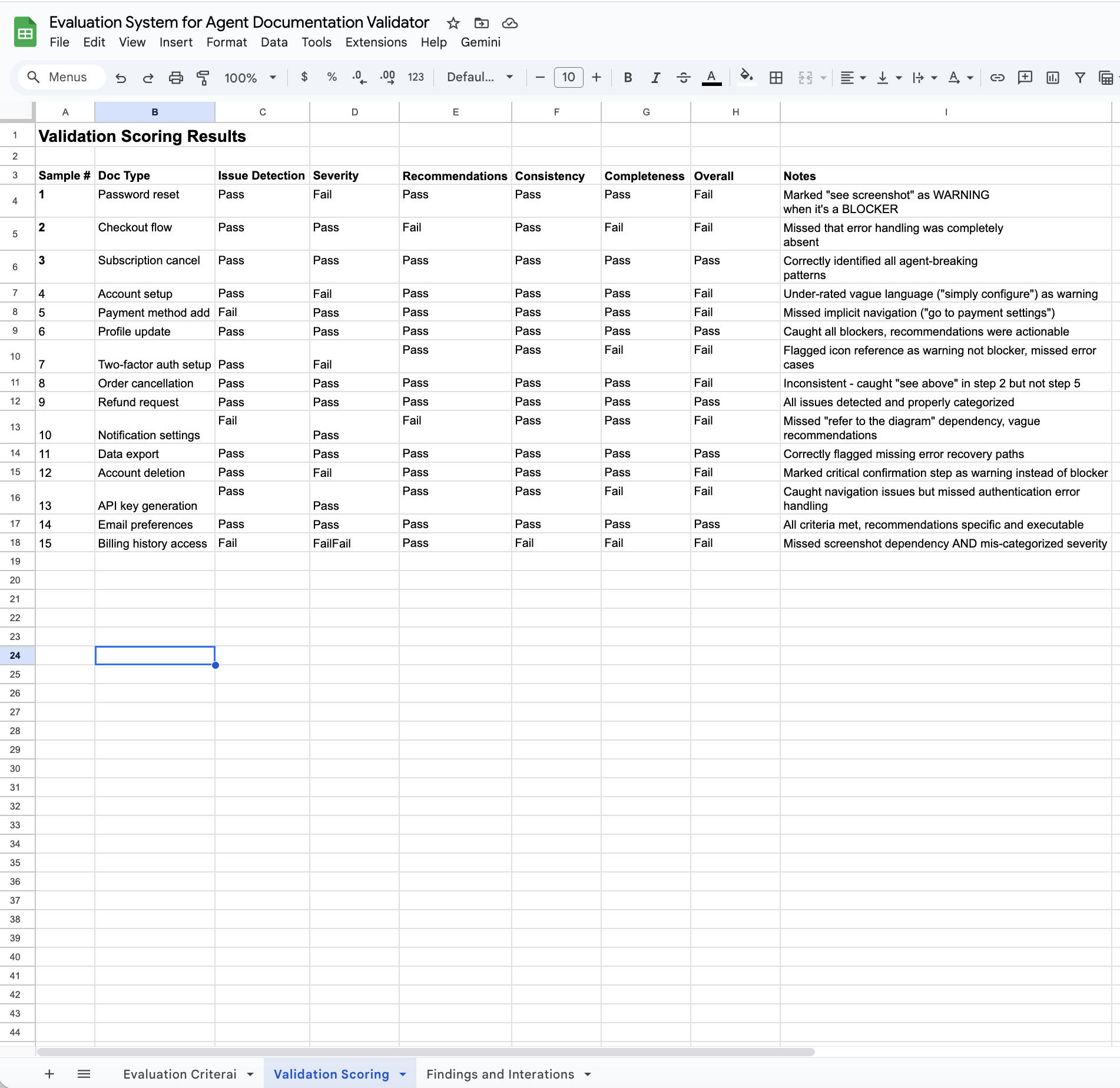
This snapshot shows how documentation samples were scored against each evaluation criterion.
This snapshot shows how recurring failure patterns informed prompt and logic improvements.

The evaluation system demonstrates:
- Criteria definition: Five standards for judging whether the validator correctly identifies agent-breaking issues
- Performance testing: Results from 15 documentation samples scored against all criteria
- Iteration process: How patterns in failures led to prompt improvements
- Measurable impact: System accuracy improved from 58% to 89% after two iterations
This example shows how governance can be applied to AI tools through clear readiness criteria, measurement, and iteration.