-
Notifications
You must be signed in to change notification settings - Fork 113
Add python keyword search quickstart #2106
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Merged
Merged
Changes from all commits
Commits
Show all changes
24 commits
Select commit
Hold shift + click to select a range
183e888
Add new python keyword search quickstart
lcawl 657c146
Merge branch 'main' into lcawl/gs-python
lcawl 43e4944
Update solutions/search/get-started/keyword-search-python.md
lcawl 6b4a507
Update solutions/search/get-started/keyword-search-python.md
lcawl ee2b737
Update solutions/search/get-started/keyword-search-python.md
lcawl d828108
Update solutions/search/get-started/keyword-search-python.md
lcawl e679259
Update solutions/search/get-started/keyword-search-python.md
lcawl 3ebeca2
Update solutions/search/get-started/keyword-search-python.md
lcawl d801c53
Merge branch 'main' into lcawl/gs-python
lcawl c547fab
Address feedback about introduction
lcawl 55f0cb0
Update solutions/search/get-started/keyword-search-python.md
lcawl 1761a00
Update solutions/search/get-started/keyword-search-python.md
lcawl 2160992
Update solutions/search/get-started/keyword-search-python.md
lcawl 9014c1f
Update solutions/search/get-started/keyword-search-python.md
lcawl 26261e5
Add project creation step and python prereqs
lcawl d43d8af
More edits
lcawl 56d3454
Improve query and next steps
lcawl 1a19a32
Update solutions/search/get-started/keyword-search-python.md
lcawl a5bf9fb
Update solutions/search/get-started/keyword-search-python.md
lcawl 88aacb9
Merge branch 'main' into lcawl/gs-python
lcawl 77795d4
Fix typo
lcawl 3469afd
Add stepper component
lcawl 3c85f7f
Merge branch 'main' into lcawl/gs-python
lcawl 0559ddc
Merge branch 'main' into lcawl/gs-python
lcawl File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,185 @@ | ||
| --- | ||
| navigation_title: "Keyword search with Python" | ||
| description: An introduction to building an Elasticsearch query in Python. | ||
| applies_to: | ||
| serverless: | ||
| elasticsearch: ga | ||
| products: | ||
| - id: elasticsearch | ||
| - id: elasticsearch-client | ||
| --- | ||
| # Build your first search query with Python | ||
|
|
||
| In this quickstart, you'll index a couple of documents and query them using [Python](https://www.python.org/). | ||
| These concepts and techniques will help you connect a backend application to {{es}} to answer your queries. | ||
|
|
||
| This quickstart also introduces you to the [official {{es}} clients](/reference/elasticsearch-clients/index.md), which are available for multiple programming languages. | ||
| These clients offer full API support for indexing, searching, and cluster management. | ||
| They are optimized for performance and kept up to date with {{es}} releases, ensuring compatibility and security. | ||
|
|
||
| This quickstart does not require previous knowledge of {{es}} but assumes a basic familiarity with Python development. | ||
| To follow the steps, you must have a recent version of a Python interpreter. | ||
|
|
||
| :::::{stepper} | ||
|
|
||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| ::::{step} Create a project | ||
|
|
||
| Create an [{{es-serverless}}](/solutions/search/serverless-elasticsearch-get-started.md) general purpose project. | ||
| To add the sample data, you must have a `developer` or `admin` predefined role or an equivalent custom role. | ||
| To learn about role-based access control, go to [](/deploy-manage/users-roles/cluster-or-deployment-auth/user-roles.md). | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| :::: | ||
| ::::{step} Create an index | ||
|
|
||
| An index is a collection of documents uniquely identified by a name or an alias. | ||
| To create an index, go to **{{es}} > Home**, select keyword search, and follow the guided workflow. | ||
|
|
||
| To enable your client to talk to your project, you must also create an API key. | ||
| Click **Create API Key** and use the default values, which are sufficient for this quickstart. | ||
|
|
||
| :::{tip} | ||
| For more information about indices and API keys, go to [](/manage-data/data-store/index-basics.md) and [](/deploy-manage/api-keys/serverless-project-api-keys.md). | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| ::: | ||
| :::: | ||
| ::::{step} Install the Python client | ||
|
|
||
| Select your preferred language in the keyword search workflow. | ||
| For this quickstart, use Python. | ||
|
|
||
| 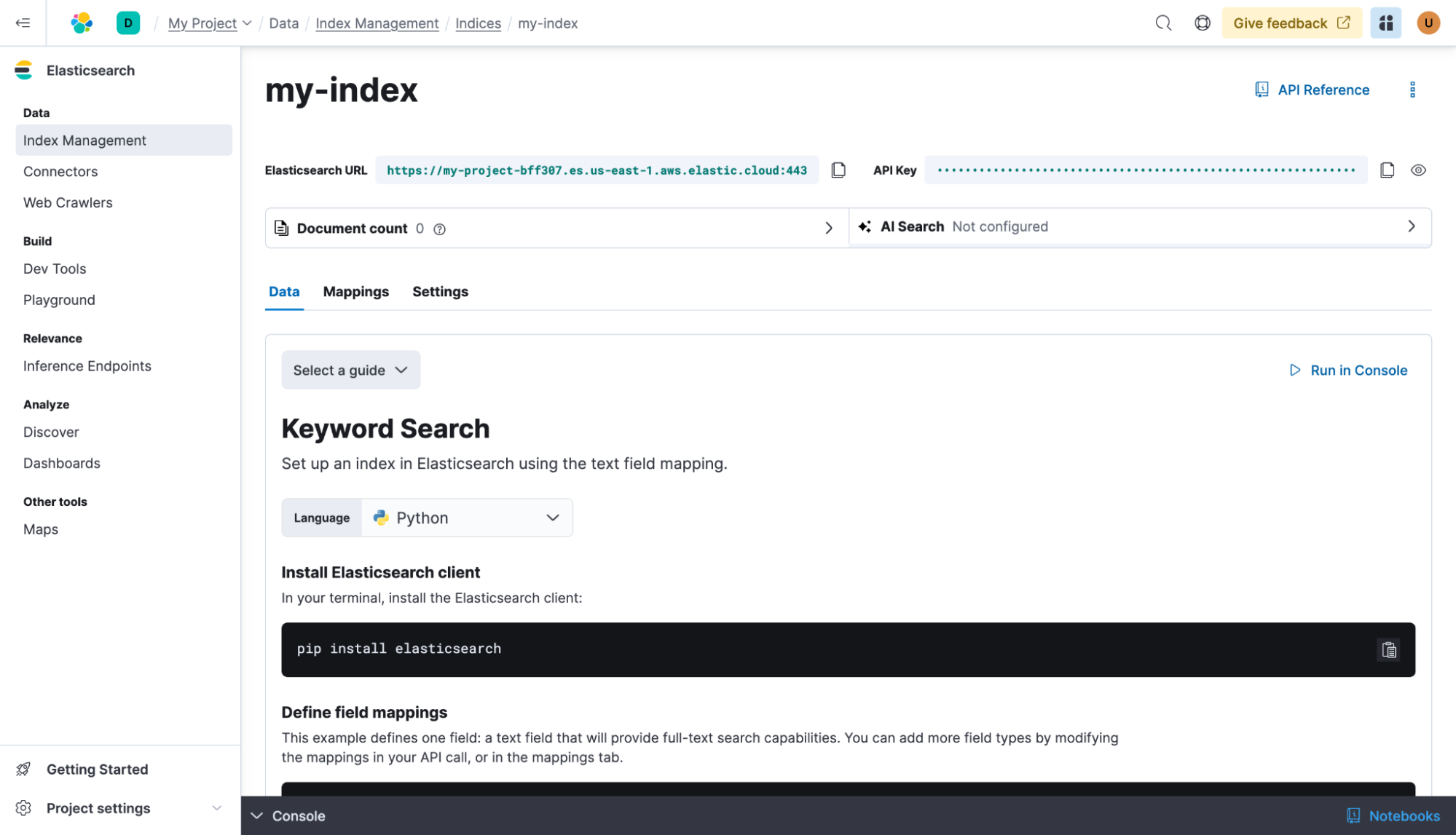 | ||
|
|
||
| The {{es}} client library is a Python package that is installed with `pip`: | ||
|
|
||
| ```py | ||
| python -m pip install elasticsearch | ||
| ``` | ||
|
|
||
| :::: | ||
| ::::{step} Connect to your project | ||
|
|
||
| To connect from your client to your {{es-serverless}} project, copy the following code example from the guided workflow into your Python interpreter in interactive mode: | ||
| For example, connect from your client to your {{es-serverless}} project: | ||
|
|
||
| ```py | ||
| from elasticsearch import Elasticsearch, helpers | ||
|
|
||
| client = Elasticsearch( | ||
| "YOUR-PROJECT-URL", | ||
| api_key="YOUR-API-KEY" | ||
| ) | ||
|
|
||
| index_name = "YOUR-INDEX" | ||
| ``` | ||
|
|
||
| You must replace the project URL, API key, and index name with the appropriate values. | ||
|
|
||
| :::: | ||
| ::::{step} Define field mappings | ||
|
|
||
| An index has mappings that define how data is stored and indexed. | ||
| Create mappings for your index, including a single text field named `text`: | ||
|
|
||
| ```py | ||
| mappings = { | ||
| "properties": { | ||
| "text": { | ||
| "type": "text" | ||
| } | ||
| } | ||
| } | ||
|
|
||
| mapping_response = client.indices.put_mapping(index=index_name, body=mappings) | ||
| print(mapping_response) | ||
| ``` | ||
|
|
||
| A successful response will acknowledge the creation of the mappings: | ||
|
|
||
| ```py | ||
| {'acknowledged': True} | ||
| ``` | ||
|
|
||
| :::: | ||
| ::::{step} Ingest documents | ||
|
|
||
| Next, use a bulk helper function to add three documents to your index. | ||
| Bulk requests are the preferred method for indexing large volumes of data, from hundreds to billions of documents. | ||
|
|
||
| ```py | ||
| docs = [ | ||
| { | ||
| "text": "Yellowstone National Park is one of the largest national parks in the United States. It ranges from the Wyoming to Montana and Idaho, and contains an area of 2,219,791 acress across three different states. Its most famous for hosting the geyser Old Faithful and is centered on the Yellowstone Caldera, the largest super volcano on the American continent. Yellowstone is host to hundreds of species of animal, many of which are endangered or threatened. Most notably, it contains free-ranging herds of bison and elk, alongside bears, cougars and wolves. The national park receives over 4.5 million visitors annually and is a UNESCO World Heritage Site." | ||
| }, | ||
| { | ||
| "text": "Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face." | ||
| }, | ||
| { | ||
| "text": "Rocky Mountain National Park is one of the most popular national parks in the United States. It receives over 4.5 million visitors annually, and is known for its mountainous terrain, including Longs Peak, which is the highest peak in the park. The park is home to a variety of wildlife, including elk, mule deer, moose, and bighorn sheep. The park is also home to a variety of ecosystems, including montane, subalpine, and alpine tundra. The park is a popular destination for hiking, camping, and wildlife viewing, and is a UNESCO World Heritage Site." | ||
| } | ||
| ] | ||
|
|
||
| bulk_response = helpers.bulk(client, docs, index=index_name) | ||
| print(bulk_response) | ||
| ``` | ||
|
|
||
| For more details about bulker helpers, refer to [Client helpers](elasticsearch-py://reference/client-helpers.md). | ||
|
|
||
| :::: | ||
| ::::{step} Explore the data | ||
|
|
||
| You should now be able to see the documents in the guided workflow: | ||
|
|
||
| 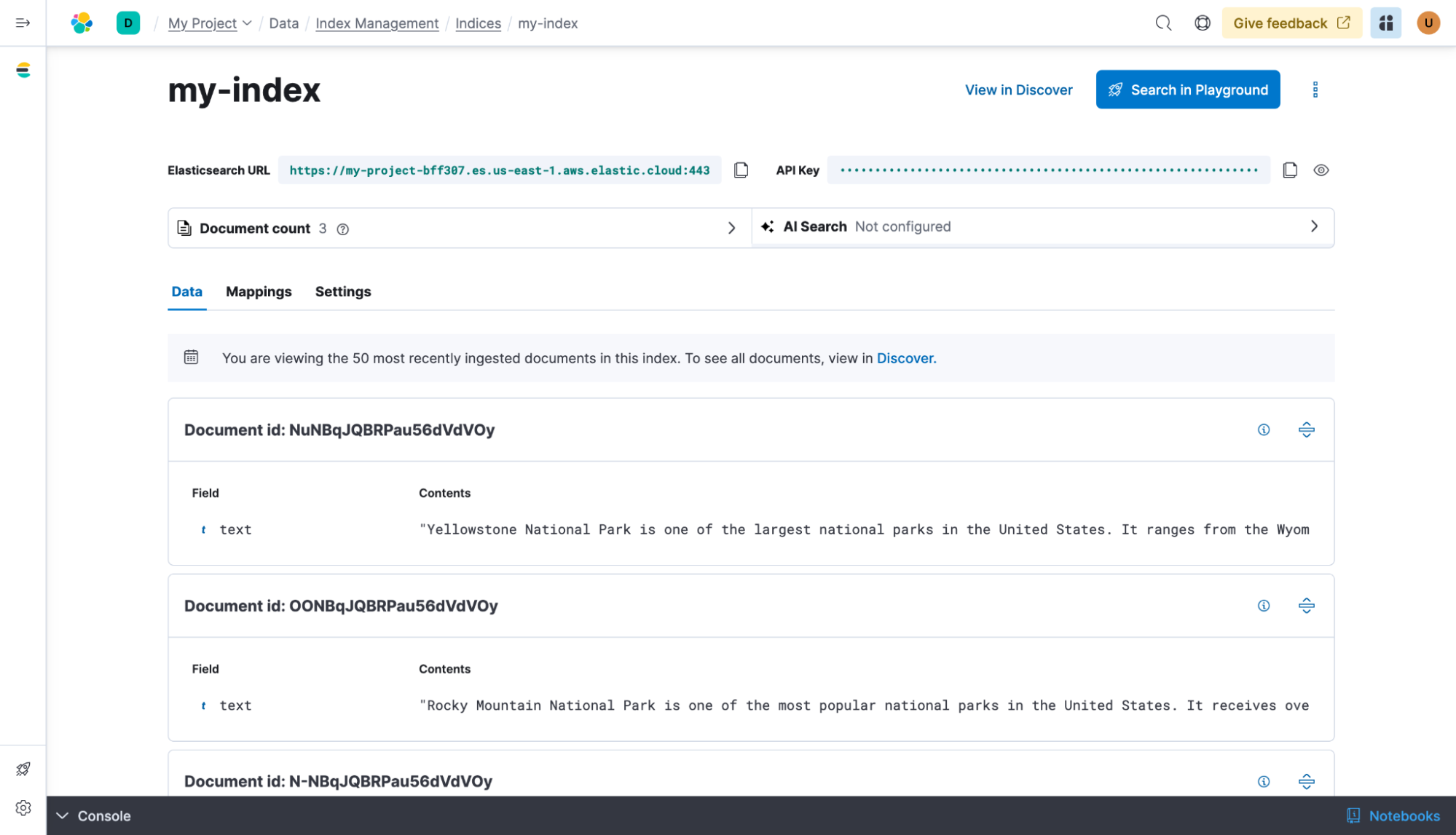 | ||
|
|
||
| Optionally open [Discover](/explore-analyze/discover.md) from the navigation menu or the [global search field](/explore-analyze/find-and-organize/find-apps-and-objects.md) to familiarize yourself with this data set. | ||
|
|
||
| :::: | ||
| ::::{step} Test keyword search | ||
|
|
||
| A keyword search, also known as lexical search or [full-text search](/solutions/search/full-text.md) finds relevant documents in your indices using exact matches, patterns, or similarity scoring. | ||
| The guided workflow provides an example that uses [Query DSL](/explore-analyze/query-filter/languages/querydsl.md). | ||
| Alternatively, try out [{{es}} Query Language](/explore-analyze/query-filter/languages/esql.md) ({{esql}}) to find documents that match a specific keyword: | ||
|
|
||
| ```py | ||
| response = client.esql.query( | ||
| query=""" | ||
| FROM * | ||
| | WHERE MATCH(text, "yosemite") | ||
| | LIMIT 5 | ||
| """, | ||
| format="csv" | ||
| ) | ||
|
|
||
| print(response) | ||
| ``` | ||
|
|
||
| :::{tip} | ||
| Instead of using the `*` wildcard, you can narrow the query by using your index name. | ||
| For more details, refer to the [ES|QL reference](elasticsearch://reference/query-languages/esql.md) | ||
| ::: | ||
|
|
||
| The results in this case contain the document that matches the query: | ||
|
|
||
| ```txt | ||
| "Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face." | ||
| Now you are ready to use the client to query Elasticsearch from any Python backend like Flask, Django, etc. Check out the Elasticsearch Python Client documentation to explore further | ||
| ``` | ||
|
|
||
| :::: | ||
| ::::: | ||
|
|
||
| ## Next steps | ||
|
|
||
| Test some more keyword search queries or go to the **{{index-manage-app}}** page and follow the workflows for vector search or semantic search queries. | ||
|
|
||
| When you finish your tests and no longer need the sample data set, delete your index: | ||
|
|
||
| ```py | ||
| client.indices.delete(index=index_name) | ||
| ``` | ||
|
|
||
| This quickstart covered the basics of working with {{es}}. | ||
| For a deeper dive, refer to the following resources: | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| - [Getting started with the Python client](elasticsearch-py://reference/getting-started.md) | ||
| - [](/manage-data/ingest/ingesting-data-from-applications/ingest-data-with-python-on-elasticsearch-service.md) | ||
| - [Python notebooks](https://github.com/elastic/elasticsearch-labs/tree/main/notebooks/README.md) | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.