TransitiveClosure
Processing of Recursive Queries in the Relational Algebra context has been a well researched topic for over 20 years; we have varying degrees of support in RDBMS for these queries. Of late this has become an interesting topic in hadoop, see HaLoop for e.g.
Couple of important things to notes are:
- An important subclass of Datalog programs are ones involving one linear recursive rule and one recursive rule.
- These can be expressed as a sequence of Relational algebra operations run to a fixed point.
- These problems can also be viewed as path problems on Graphs. There are class of path problems on cyclic graphs with positive labels that are guaranteed to terminate. This set of problems include common problems like reachability, shortest path, bill of material, max capacity, most reliable path etc.
- Given the dual way of viewing these problems there are 2 general approaches to solving these: iterative algorithms that provide a solution based on relational operators or direct algorithms which view the input as an Adjacency matrix of the graph.
A dated but very comprehensive survey of this field can be found in the paper: A Survey of Parallel Execution Strategies for Transitive Closure and Logic Programs by Cacace, Ceri and Houtsma.
In the following:
- we provide details about the Transitive closure problem. This involves finding all the possible paths in a Graph, or finding all the possible related items in a Relationship.
- we briefly document the Semi Naive Algorithm
- show its possible implementaion using Hive statements
- then we provide a possible solution using a Partitioned table Function stragey.
- We then discuss how this solution can be generalized for other Path Problems.
- Finally we talk about how a PTF solution relates to a Giraph and Haloop.
Is a basic distributed Iterative Algorithm that runs to a fixed point. It can be understood by the phrase; Join, Distribute, DeDup; each iteration of the algorithm does a join of the base relation with any any tuples found from the previous iteration; the new tuples are repartitioned and any duplicate paths are eliminated from the set of new paths. The process is repeated until no new paths are found.
Input: I(X, Y) Output; R(X,Y) T = distribute I by column Y R = distribute I by column X deltaR = R while deltaR is not empty deltaRnext = T join deltaR, then distribute by X deltaR = deltaRnext - R R = R union deltaR

The communication cost of the Algorithm in terms of number of tuples is equal to the number of Paths in the Graph. At the end of the Join every Path is communicated to the Node that owns that Path. In addition there is an initialization cost of distributing the input relation over the cluster.
It is fairly easy to express the steps of the Semi Naive Algorithm
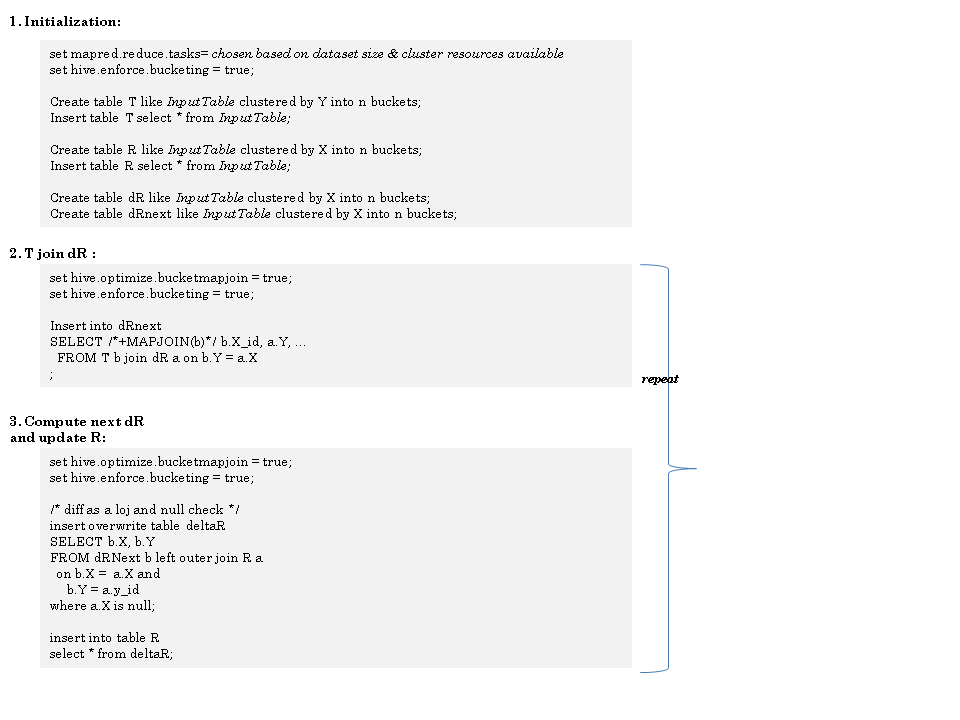
Step 2 in the Hive implementation matches the psuedo code above: a MapJoin ensures only the new Paths are communicated over the cluster.
But since we cannot control whether R and deltaRnext are colocated, in Step 3:
- at best we hope to recommunicate all Paths ie do a MapJoin on nodes were R.
- other options which are worse are communicate R; which in the worse case over all iterations could involve communicating the entire closure relation multiple times over the n/w; even worse is a simpleJoin plan were both R and deltaRnext will be communicated over the n/w.

- Assume that the output R is maintained as a directory of sub directories. Each subsirectory corresponds to a partition of R; and it contains a set of deltaR files; each file is the list of new paths in iteration i.
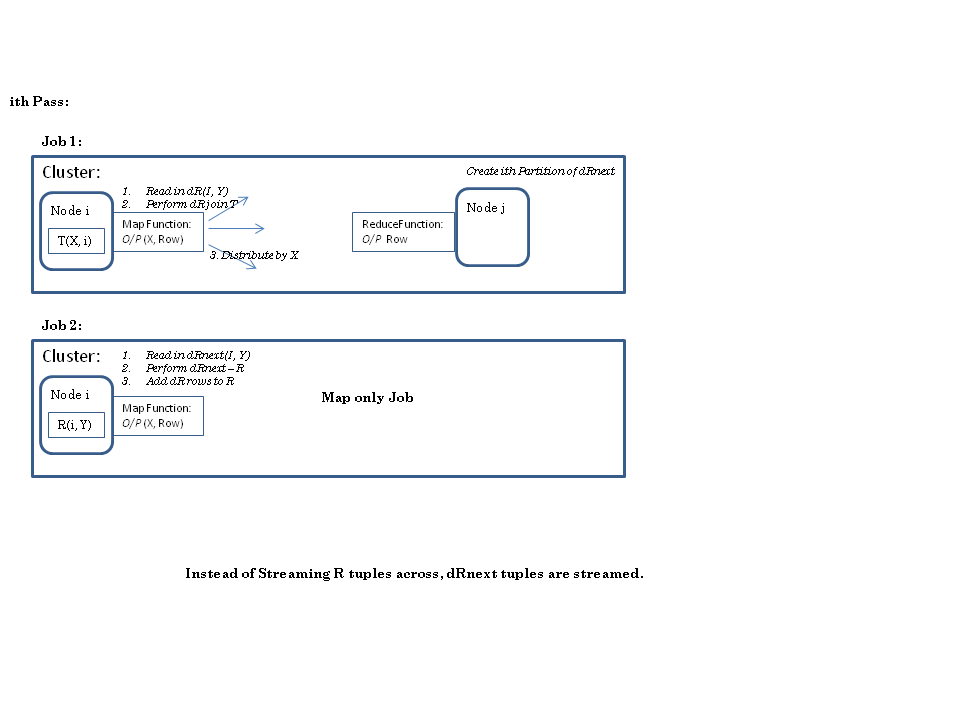
- The ith iteration involves execution of Table operations at the Map
and Reduce side:
- On the Map side a partition of T is joined with the corresponding deltaR; this is similar to a MapJoin in Hive.
- On the Reduce side the new paths from deltaNextR are held in a searchable structure; the rows of the corresponding R partition are streamed to mark any rows in deltaNextR that are duplicates. At the end a new file is stored in the correponding R partition with the new paths.
The map side processing involves reading in deltaR tuples; this is exactly like the above to cases. But on the reduce side the reducer runs at a deltaRnext partition, so the tuples of R need to be streamed.
Note that is the absolute worst option we could pick. The important thing to note is that this execution plan is easy to fit into the generic PTF execution framework. transtiveClosure can be written as any other existing PTF. An additional fetaure have to be added to the framework:
- at the end of executing a Job for the function; the function should be allowed to ask the framework to run another Job on the same input.
Couple of things we can do to imporve performance is:
- since we are writing the deltaR tables, we can maintain an index which can quickly tell us of the existence a path in a file. This would imply we don’t stream the entire R relation over the n/w but only the index.
- An even more effective thing to do is to run the deDup step where R is:
But this is harder to fit into the general framework. This requires running a Job on R, which is not the original input, nor is it the output of the Reduce phase (so the 2 Jobs cannot be expressed as Function Chain). This would require the transitiveClosure function to spawn a Job when it is asked to check for the stop condition. Since we already support executing embedded Hive Queries, it maybe conceivable to allow functions to use this feature.