This project implements a core console-based content moderation system designed to automatically detect and flag inappropriate content in text-based user-generated content. While our current implementation focuses on the fundamental algorithms and data structures required for content detection and flagging, this README provides context on the larger problem space and how this system would scale to handle real-world applications like those used by major tech platforms.
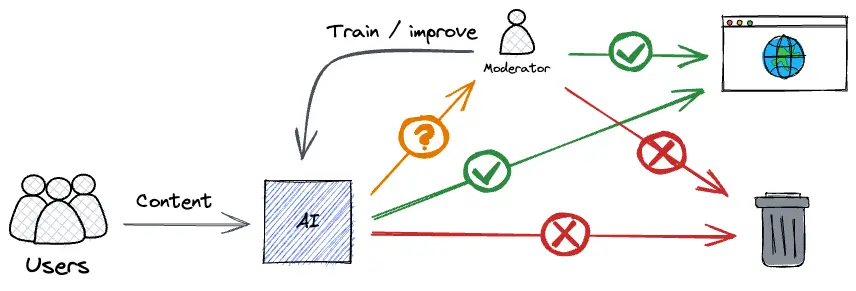
In today's digital landscape, platforms like Facebook, Twitter, YouTube, and other social media networks face an enormous challenge: moderating millions of pieces of user-generated content every second. This content can include:
- Hate speech and harassment
- Violent threats
- Misinformation
- Scams and fraud
- Adult content
- Other forms of harmful material
Manual moderation is:
- Too slow for real-time interactions
- Unable to scale to handle millions of users
- Psychologically taxing on human moderators
- Inconsistent across different moderators and regions
Our system aims to address these challenges by providing automated, algorithmic content moderation that can:
- Detect inappropriate content in real-time
- Scale to handle large volumes of data
- Adapt to evolving language and contexts
- Incorporate user feedback to continuously improve
Our current console application demonstrates the fundamental building blocks of a content moderation system:
-
Trie-based Content Detection
- Uses a Trie (prefix tree) data structure to efficiently store and search for banned words
- Provides O(m) lookup time where m is the length of the word
- Enables real-time filtering even for large dictionaries of banned terms
-
Graph-based Relationship Modeling
- Represents relationships between inappropriate terms
- Models how different harmful terms are connected
- Reveals potential emerging threats based on term associations
-
BFS Pathfinding Visualization
- Uses Breadth-First Search algorithm to traverse the graph
- Identifies and displays related inappropriate terms
- Helps human moderators understand the context of flagged content
-
Feedback Loop System
- Collects user feedback on flagged content
- Stores data that could be used for system improvement
- Forms the foundation for an adaptive learning system
graph TD
A[User Inputs Content] --> B[Content Tokenization]
B --> C[Trie-based Matching]
C --> D{Contains Banned Words?}
D -->|Yes| E[Flag Content]
D -->|No| F[Approve Content]
E --> G[BFS for Related Terms]
G --> H[Display Flagging Results]
H --> I[Collect User Feedback]
I --> J[Store Feedback]
J --> K[Update Statistics]
-
Trie (Prefix Tree)
- Used for efficient word lookup
- Time Complexity: O(m) where m is the length of the word
- Space Complexity: O(n*m) where n is the number of words
-
Graph (Adjacency List)
- Space Complexity: O(V + E) where V is the number of vertices and E is the number of edges
- Used to model term relationships
-
Breadth-First Search (BFS)
- Time Complexity: O(V + E)
- Used to find related terms within a certain distance
-
Hash Maps
- O(1) average lookup time
- Used for term frequency tracking and relationship storage
ContentModerationSystem
├── TrieNode Class
│ ├── Store banned words
│ └── Efficient lookup
├── Graph Class
│ ├── Store term relationships
│ └── BFS traversal for related terms
└── ContentModerationSystem Class
├── loadBannedWords()
├── addTermRelationship()
├── flagContent()
├── processContent()
├── collectFeedback()
├── visualizeTermGraph()
└── showStatistics()
In a production environment at companies like Google, Facebook, or Twitter, this core implementation would be part of a much larger system:
graph TD
A[User Content] --> B[Load Balancer]
B --> C1[Content Analysis Service 1]
B --> C2[Content Analysis Service 2]
B --> C3[Content Analysis Service n]
C1 --> D[Distributed Cache]
C2 --> D
C3 --> D
C1 --> E[Distributed Database]
C2 --> E
C3 --> E
D --> F[ML Model Service]
E --> F
F --> G[Result Aggregator]
G --> H{Decision}
H -->|Flagged| I[Review Queue]
H -->|Approved| J[Content Published]
I --> K[Human Review]
K --> L[Feedback Loop]
L --> F
-
Content Ingestion Layer
- Kafka/RabbitMQ for message queuing
- Load balancing for horizontal scaling
- Rate limiting to prevent abuse
-
Processing Layer
- Distributed Trie implementation (sharded by term prefixes)
- In-memory caching for frequently searched terms
- Bloom filters for fast negative lookups
-
ML Enhancement Layer
- BERT/GPT models for contextual understanding
- CNN models for image moderation
- Embeddings for semantic relationship detection
-
Storage Layer
- Graph databases (Neo4j/TigerGraph) for term relationships
- Distributed key-value stores for term metadata
- Time-series databases for trend analysis
-
Feedback Layer
- Active learning for model improvement
- Human review integration
- A/B testing for algorithm refinement
- Uses a combination of AI and human moderators
- Employs computer vision for image and video content
- Utilizes natural language processing for text analysis
- Implements multi-stage filtering:
- Automated pre-screening
- Risk-based prioritization
- Human review for complex cases
- Appeals process
- Uses Content ID for copyright violation detection
- Implements ML models for inappropriate content detection
- Applies community guidelines based on:
- Video content
- Thumbnail analysis
- Comment section monitoring
- Channel history and reliability
- Uses ML-based filtering for tweets and direct messages
- Implements graph-based algorithms to detect coordinated harmful activity
- Utilizes behavior patterns to identify bots and spam accounts
- Provides user controls for filtering their experience
-
Social Media Platforms
- Real-time comment and post moderation
- Private message scanning for harmful content
- Group and community management
-
Online Marketplaces
- Product listing moderation
- Review and feedback filtering
- Seller communication monitoring
-
Online Gaming
- In-game chat moderation
- User-generated content filtering
- Player behavior analysis
-
Educational Platforms
- Student interaction monitoring
- Assignment submission scanning
- Discussion forum moderation
-
Customer Service Systems
- Support ticket prioritization
- Automated response filtering
- Customer feedback analysis
Our core implementation can be extended with:
-
Advanced NLP Integration
- Sentiment analysis for context understanding
- Embedding-based similarity for slang detection
- Language models for contextual understanding
-
Multi-modal Analysis
- Image recognition for visual content moderation
- Audio transcription and analysis
- Video content scanning
-
Distributed Architecture
- Sharding for horizontal scaling
- Replication for fault tolerance
- Load balancing for performance optimization
-
Real-time Streaming
- Kafka/Kinesis integration for real-time processing
- Time-window analysis for trend detection
- Rate limiting and throttling mechanisms
-
Dashboard and Visualization
- Real-time monitoring of system performance
- Trend analysis and visualization
- User behavior insights
Our content moderation system demonstrates the core algorithmic foundations of modern content moderation platforms. While our implementation is focused on a console application showing the essential components, the same principles and algorithms are applied at massive scale by tech giants to moderate billions of content pieces daily.
The use of efficient data structures like Tries and Graphs, combined with algorithms like BFS, forms the backbone of these systems. As content moderation continues to evolve, incorporating machine learning, multi-modal analysis, and sophisticated feedback loops will further enhance these systems' capabilities.
By understanding the fundamentals implemented in our project, developers can gain insight into how large-scale content moderation works and how these principles can be applied to create safer online spaces.
- C++ compiler with C++17 support
- Standard libraries
- Clone the repository
git clone https://github.com/kartik4042/Content-Moderation-System.git- Compile the code
cd Content-Moderation-System
g++ -std=c++17 main.cpp -o Content_Moderation_System- Run the application
Content_Moderation_System.exeContributions are welcome! Please feel free to submit a Pull Request.