|
70 | 70 | "source": [ |
71 | 71 | "import os\n", |
72 | 72 | "import tempfile\n", |
| 73 | + "from datetime import datetime\n", |
73 | 74 | "\n", |
| 75 | + "from matplotlib import pyplot as plt\n", |
74 | 76 | "from torch.utils.data import DataLoader\n", |
75 | 77 | "\n", |
76 | 78 | "from torchgeo.datasets import CDL, BoundingBox, Landsat7, Landsat8, stack_samples\n", |
77 | | - "from torchgeo.datasets.utils import download_url\n", |
| 79 | + "from torchgeo.datasets.utils import download_and_extract_archive\n", |
78 | 80 | "from torchgeo.samplers import GridGeoSampler, RandomGeoSampler" |
79 | 81 | ] |
80 | 82 | }, |
|
102 | 104 | "\n", |
103 | 105 | "Traditionally, people either performed classification on a single pixel at a time or curated their own benchmark dataset. This works fine for training, but isn't really useful for inference. What we would really like to be able to do is sample small pixel-aligned pairs of input images and output masks from the region of overlap between both datasets. This exact situation is illustrated in the following figure:\n", |
104 | 106 | "\n", |
105 | | - "![Landsat CDL intersection]()\n", |
| 107 | + "\n", |
106 | 108 | "\n", |
107 | 109 | "Now, let's see what features TorchGeo has to support this kind of use case." |
108 | 110 | ] |
|
141 | 143 | "source": [ |
142 | 144 | "landsat_root = os.path.join(tempfile.gettempdir(), 'landsat')\n", |
143 | 145 | "\n", |
144 | | - "download_url()\n", |
145 | | - "download_url()\n", |
| 146 | + "url = 'https://hf.co/datasets/torchgeo/tutorials/resolve/ff30b729e3cbf906148d69a4441cc68023898924/'\n", |
| 147 | + "landsat7_url = url + 'LE07_L2SP_022032_20230725_20230820_02_T1.tar.gz'\n", |
| 148 | + "landsat8_url = url + 'LC08_L2SP_023032_20230831_20230911_02_T1.tar.gz'\n", |
146 | 149 | "\n", |
147 | | - "landsat7 = Landsat7(\n", |
148 | | - " paths=landsat_root, bands=['B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7']\n", |
149 | | - ")\n", |
150 | | - "landsat8 = Landsat8(\n", |
151 | | - " paths=landsat_root, bands=['B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8']\n", |
152 | | - ")\n", |
| 150 | + "download_and_extract_archive(landsat7_url, landsat_root)\n", |
| 151 | + "download_and_extract_archive(landsat8_url, landsat_root)\n", |
| 152 | + "\n", |
| 153 | + "landsat7_bands = ['SR_B1', 'SR_B2', 'SR_B3', 'SR_B4', 'SR_B5', 'SR_B7']\n", |
| 154 | + "landsat8_bands = ['SR_B2', 'SR_B3', 'SR_B4', 'SR_B5', 'SR_B6', 'SR_B7']\n", |
| 155 | + "\n", |
| 156 | + "landsat7 = Landsat7(paths=landsat_root, bands=landsat7_bands)\n", |
| 157 | + "landsat8 = Landsat8(paths=landsat_root, bands=landsat8_bands)\n", |
153 | 158 | "\n", |
154 | 159 | "print(landsat7)\n", |
155 | | - "print(landsat8)" |
| 160 | + "print(landsat8)\n", |
| 161 | + "\n", |
| 162 | + "print(landsat7.crs)\n", |
| 163 | + "print(landsat8.crs)" |
156 | 164 | ] |
157 | 165 | }, |
158 | 166 | { |
|
186 | 194 | "source": [ |
187 | 195 | "cdl_root = os.path.join(tempfile.gettempdir(), 'cdl')\n", |
188 | 196 | "\n", |
189 | | - "download_url()\n", |
| 197 | + "cdl_url = url + '2023_30m_cdls.zip'\n", |
| 198 | + "\n", |
| 199 | + "download_and_extract_archive(cdl_url, cdl_root)\n", |
190 | 200 | "\n", |
191 | 201 | "cdl = CDL(paths=cdl_root)\n", |
192 | 202 | "\n", |
193 | | - "print(cdl)" |
| 203 | + "print(cdl)\n", |
| 204 | + "print(cdl.crs)" |
194 | 205 | ] |
195 | 206 | }, |
196 | 207 | { |
|
201 | 212 | "Again, the following details are worth noting:\n", |
202 | 213 | "\n", |
203 | 214 | "* We could actually ask the `CDL` dataset to download our data for us by adding `download=True`\n", |
204 | | - "* All three datasets have different spatial extends\n", |
205 | | - "* All three datasets have different CRSs" |
| 215 | + "* All datasets have different spatial extents\n", |
| 216 | + "* All datasets have different CRSs" |
206 | 217 | ] |
207 | 218 | }, |
208 | 219 | { |
|
223 | 234 | "outputs": [], |
224 | 235 | "source": [ |
225 | 236 | "landsat = landsat7 | landsat8\n", |
226 | | - "print(landsat)" |
| 237 | + "print(landsat)\n", |
| 238 | + "print(landsat.crs)" |
227 | 239 | ] |
228 | 240 | }, |
229 | 241 | { |
|
242 | 254 | "outputs": [], |
243 | 255 | "source": [ |
244 | 256 | "dataset = landsat & cdl\n", |
245 | | - "print(dataset)" |
| 257 | + "print(dataset)\n", |
| 258 | + "print(dataset.crs)" |
246 | 259 | ] |
247 | 260 | }, |
248 | 261 | { |
|
262 | 275 | "\n", |
263 | 276 | "How did we do this? TorchGeo uses a data structure called an *R-tree* to store the spatiotemporal bounding box of every file in the dataset. \n", |
264 | 277 | "\n", |
265 | | - "![R-tree]()\n", |
| 278 | + "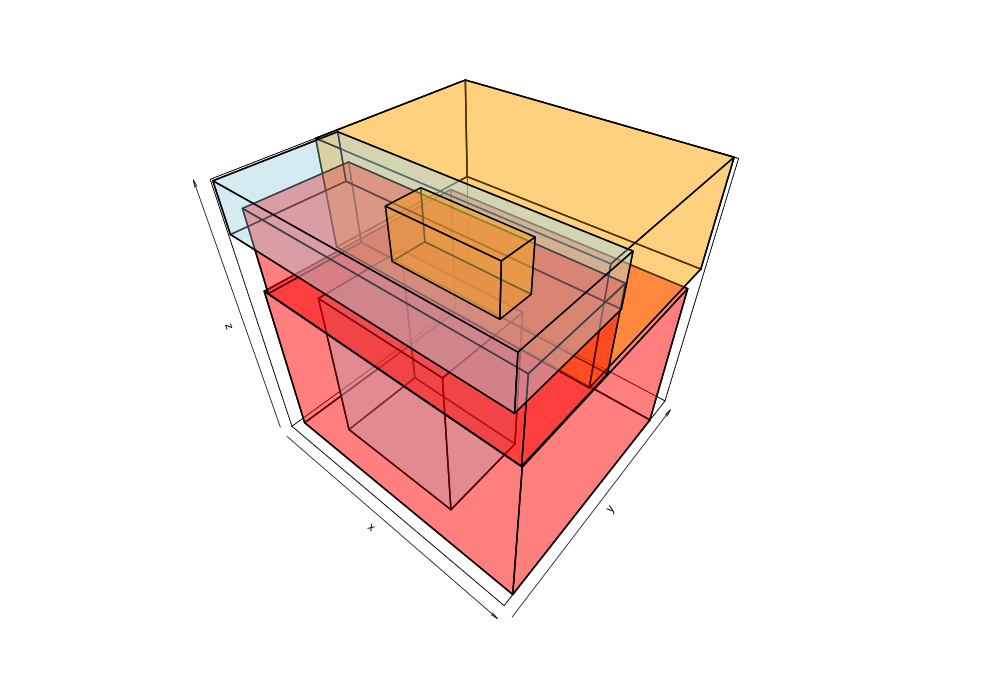\n", |
266 | 279 | "\n", |
267 | 280 | "TorchGeo extracts the spatial bounding box from the metadata of each file, and the timestamp from the filename. This geospatial and geotemporal metadata allows us to efficiently compute the intersection or union of two datasets. It also lets us quickly retrieve an image and corresponding mask for a particular location in space and time." |
268 | 281 | ] |
|
274 | 287 | "metadata": {}, |
275 | 288 | "outputs": [], |
276 | 289 | "source": [ |
277 | | - "bbox = BoundingBox()\n", |
278 | | - "sample = dataset[sample]\n", |
| 290 | + "size = 256\n", |
279 | 291 | "\n", |
280 | | - "landsat.plot(sample)\n", |
281 | | - "cdl.plot(sample)" |
| 292 | + "xmin = 925000\n", |
| 293 | + "xmax = xmin + size * 30\n", |
| 294 | + "ymin = 4470000\n", |
| 295 | + "ymax = ymin + size * 30\n", |
| 296 | + "tmin = datetime(2023, 1, 1).timestamp()\n", |
| 297 | + "tmax = datetime(2023, 12, 31).timestamp()\n", |
| 298 | + "\n", |
| 299 | + "bbox = BoundingBox(xmin, xmax, ymin, ymax, tmin, tmax)\n", |
| 300 | + "sample = dataset[bbox]\n", |
| 301 | + "\n", |
| 302 | + "landsat8.plot(sample)\n", |
| 303 | + "cdl.plot(sample)\n", |
| 304 | + "plt.show()" |
282 | 305 | ] |
283 | 306 | }, |
284 | 307 | { |
|
289 | 312 | "TorchGeo uses *windowed-reading* to only read the blocks of memory needed to load a small patch from a large raster tile. It also automatically reprojects all data to the same CRS and resolution (from the first dataset). This can be controlled by explicitly passing `crs` or `res` to the dataset." |
290 | 313 | ] |
291 | 314 | }, |
292 | | - { |
293 | | - "cell_type": "markdown", |
294 | | - "id": "02368e20-3391-4be7-bbe5-5a3c367ab398", |
295 | | - "metadata": {}, |
296 | | - "source": [ |
297 | | - "### Geospatial splitting\n", |
298 | | - "\n" |
299 | | - ] |
300 | | - }, |
301 | 315 | { |
302 | 316 | "cell_type": "markdown", |
303 | 317 | "id": "e2e4221e-dfb7-4966-96a6-e52400ae266c", |
|
327 | 341 | "metadata": {}, |
328 | 342 | "outputs": [], |
329 | 343 | "source": [ |
330 | | - "train_sampler = RandomGeoSampler(dataset, size=256, length=1000)\n", |
331 | | - "print(next(train_sampler))" |
| 344 | + "train_sampler = RandomGeoSampler(dataset, size=size, length=1000)\n", |
| 345 | + "next(iter(train_sampler))" |
332 | 346 | ] |
333 | 347 | }, |
334 | 348 | { |
|
338 | 352 | "source": [ |
339 | 353 | "### Gridded sampling\n", |
340 | 354 | "\n", |
341 | | - "At evaluation time, this actually becomes a problem. We want to make sure we aren't making multiple predictions for the same location. We also want to make sure we don't miss any locations. To achieve this, TorchGeo also provides a `GridGeoSampler`. We can tell the sampler the size of each image patch and the stride of our sliding window (defaults to patch size)." |
| 355 | + "At evaluation time, this actually becomes a problem. We want to make sure we aren't making multiple predictions for the same location. We also want to make sure we don't miss any locations. To achieve this, TorchGeo also provides a `GridGeoSampler`. We can tell the sampler the size of each image patch and the stride of our sliding window." |
342 | 356 | ] |
343 | 357 | }, |
344 | 358 | { |
|
348 | 362 | "metadata": {}, |
349 | 363 | "outputs": [], |
350 | 364 | "source": [ |
351 | | - "test_sampler = GridGeoSampler(dataset, size=256)\n", |
352 | | - "print(next(test_sampler))" |
| 365 | + "test_sampler = GridGeoSampler(dataset, size=size, stride=size)\n", |
| 366 | + "next(iter(test_sampler))" |
353 | 367 | ] |
354 | 368 | }, |
355 | 369 | { |
|
379 | 393 | }, |
380 | 394 | { |
381 | 395 | "cell_type": "markdown", |
382 | | - "id": "3518c7d9-1bb3-4bc2-8216-53044d0b4009", |
| 396 | + "id": "e46e8453-df25-4265-a85b-75dce7dea047", |
383 | 397 | "metadata": {}, |
384 | 398 | "source": [ |
385 | | - "\n", |
386 | | - "* Transforms?\n", |
387 | | - "* Models\n", |
388 | | - " * U-Net + pre-trained ResNet\n", |
389 | | - " * Model pre-trained directly on satellite imagery\n", |
390 | | - "* Training and evaluation\n", |
391 | | - " * Copy everything else from " |
| 399 | + "Now that we have working data loaders, we can copy-n-paste our training code from the Introduction to PyTorch tutorial. We only need to change our model to one designed for semantic segmentation, such as a U-Net. Every other line of code would be identical to how you would do this in your normal PyTorch workflow." |
392 | 400 | ] |
393 | 401 | }, |
394 | 402 | { |
|
403 | 411 | "* [TorchGeo: Deep Learning With Geospatial Data](https://arxiv.org/abs/2111.08872)\n", |
404 | 412 | "* [Geospatial deep learning with TorchGeo](https://pytorch.org/blog/geospatial-deep-learning-with-torchgeo/)" |
405 | 413 | ] |
406 | | - }, |
407 | | - { |
408 | | - "cell_type": "code", |
409 | | - "execution_count": null, |
410 | | - "id": "38e60635-69b2-47c9-8df2-fd7c872abdd9", |
411 | | - "metadata": {}, |
412 | | - "outputs": [], |
413 | | - "source": [] |
414 | 414 | } |
415 | 415 | ], |
416 | 416 | "metadata": { |
|
0 commit comments