The project works only on Aljazeera website.
The project has 2 files :
- moduleScraping.py which is based on the beautifulsoup and requests only to scrape the latest articles of the current day
- modulesScrapingHistoricalArticles.py based on beautifulsoup and selenium to scrape the historical data from the Aljazeera website with automating the process
The most magical part about the project is that you can customize the code for your own needs based on :
- What type of articles (Categories: economy, sports, news...) and the amount of data you want to scrape from the site, and based on your choice you will pick only one file from the two files present in the repository.
- You can choose the categories and also the number of categories you want to have in your CSV file.
- You can use the requirements.txt but to be more precise the libraries used are : lxml, selenium (only for the second file if it is the aimed one), Beautifulsoup, requests, pandas and csv.
- Other thing to mention : I used the chromeDriver.exe in the second file for the purpose of using selenium you can find the link for all the versions to download here, pick the one that matches the version of your google Chrome (preferred)
- The commands used to install the libraries for windows (Common libraries for the 2 files):
pip install lxmlpip install beautifulsoup4pip install requestspip install pandas- The commands used to install the required libraries specific only to the second file (moduleScrapingHistoricalArticles.py) :
pip install seleniumpip install webdriver-managerAfter installing the requirements and trying to run the file of your choice, you may encounter some errors, just be patient and try tp solve them !
If everything is set up correctly, the execution must look like this :

Then you can choose one category.
And you can customize the number of categories in the function aggragate_all() : You can choose the number of categories, so the prompt will appear until choosing all the categories (an example for 3 as an argument for the fucntion is below)
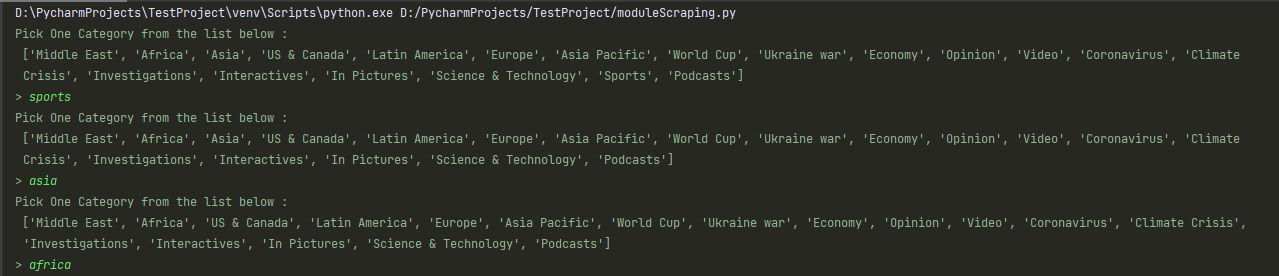
You will see the same prompt for the 2 files even if they are different cases of use.
The only difference is in the function extract_links_from_link_category() which is programmed differently :
- For extracting just the newest articles in a specific category in a specific day i used just Beautifulsoup.
- For having a large dataset of articles you use the moduleScrapingHistoricalArticles.py where the function extract_links_from_link_category() uses selenium to automate the click on the Show more button to have access to older articles and then the other functions manage all this and give you a CSV file with 3 attributes the category, the title of the article, and the content of the article at the end.
Note : You can access more articles by changing the number_of_clicks variable inside the same function, the bigger the number, the largest your dataset will be
Note : The csv files in the repository are examples of the output of the program.
I have included a sample dataset in this repository, which was downloaded using the code provided here. You can access the dataset on Kaggle using the following link: https://www.kaggle.com/datasets/oumaymael/aljazeera-news-dataset/ This dataset serves as a demonstration of the functionality of my code and can be used to replicate the results or to experiment with different analyses.